반응형
아래 데이터에서 X1과 X2의 평균을 각각 µ1, µ2라고 할 때, (µ1 - µ2)에 대한 95% 신뢰구간을 구하라.
import numpy as np
import pandas as pd
np.random.seed(1234)
X1 = np.random.normal(loc=5, scale=2, size=100)
X2 = np.random.normal(loc=5.5, scale=2, size=100)
df = pd.DataFrame({"X1": X1, "X2": X2})
df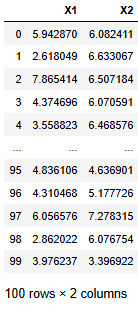
귀무가설 : µ1 - µ2는 0이다.
대립가설 : µ1 - µ2는 0이 아니다.
검정 통계량
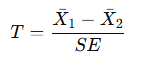

위의 식을 참고하여 아래와 같이 구할 수 있다.
from scipy.stats import norm
n1, n2 = len(df["X1"]), len(df["X2"])
mu1, mu2 = df["X1"].mean(), df["X2"].mean()
std1, std2 = df["X1"].std(), df["X2"].std()
var1, var2 = df["X1"].var(ddof=1), df["X2"].var(ddof=1)
n1, n2 = len(df["X1"]), len(df["X2"])
alpha = 0.05
z = norm.ppf(1 - alpha/2) # P(Z < Z0) = 0.975
low = (mu1 - mu2) - z * np.sqrt((std1**2 / n1) + std2**2 / n2)
up = (mu1 - mu2) + z * np.sqrt((std1**2 / n1) + std2**2 / n2)
dist = up - low
dist # 1.099999594459861반응형
'개발 > Python' 카테고리의 다른 글
| 카이제곱 검정 (0) | 2025.09.14 |
|---|---|
| DecisionTree Hyper Parameters and Attributes (0) | 2025.09.08 |
| 병합적 군집분석 계산 방법 비교 (linkage) (0) | 2025.09.08 |
| XGBoost Hyper Parameters and Attributes (0) | 2025.09.08 |
| 군집화 비교 (0) | 2025.09.08 |



댓글