반응형
다음 데이터를 4개의 구간으로 나누어라.
score1 : 하위 25%부터 0, 1, 2, 3으로 구간화
score2 : 하위 25%부터 Q1, Q2, Q3, Q4로 구간화
score3 : 상위 25%부터 0, 1, 2, 3으로 구간화
import pandas as pd
import numpy as np
# 예시 데이터프레임
df = pd.DataFrame({
'score1': [10, 20, 30, 40, 50, 60, 70, 80, 90, 100],
'score2': [100, 90, 80, 70, 60, 50, 40, 30, 20, 10],
'score3': [10, 100, 30, 20, 50, 70, 90, 80, 60, 40]
})
df
1. qcut에서 q=4, labels=False 옵션을 주면 하위 데이터부터 0, 1, 2, 3이 할당된다.
# score를 4개의 구간(사분위수)로 나누기
df['quantile1'] = pd.qcut(df['score1'], q=4, labels=False)
2. labels에 원하는 라벨링 리스트를 추가하면 된다.
df['quantile2'] = pd.qcut(df['score2'], q=4, labels=['Q1', 'Q2', 'Q3', 'Q4'])
3. 상위 데이터부터 범주화하는 옵션은 없어서, 데이터를 음수로 변환하여 처리하면 된다.
df['quantile3'] = pd.qcut(-df['score3'], q=4, labels=False)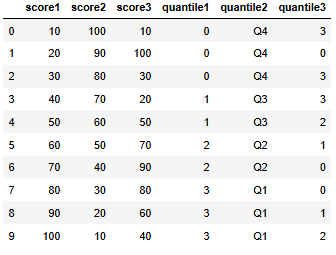
다음 데이터를 표준 정규 분포 기준으로 구간화하여라
| 조건 | label | |
| X < -Z0 | 0 | 하위 25% |
| -Z0 <= X < Z0 | 1 | 하위 25% ~ 상위 25% |
| X >= Z0 | 2 | 상위 25% |
표준정규분포 Z에 대해 Z0는 P(Z < -Z0) = 0.25를 만족한다.
import numpy as np
import pandas as pd
np.random.seed(1234)
df = pd.DataFrame(
np.random.randn(100, 1), # 표준정규분포 데이터
columns=["X"]
)
df
구간화를 하기 위해 Z0 값을 찾자.
P(Z < -Z0) = 0.25 → P(Z < Z0) = 0.75를 이용해서 Z0를 구할 수 있다.
from scipy.stats import norm
Z0 = norm.ppf(0.75)
Z0 # 0.6744897501960817
cdf에 Z0를 넣으면 0.75가 나오는 것을 알 수 있다. (검산)
norm.cdf(Z0) # 0.75
이제 numpy의 where를 이용해 구간화하면 된다.
df['label'] = np.where(df['X'] < -Z0, 0, np.where(df['X'] < Z0, 1, 2))
df
반응형
'개발 > Python' 카테고리의 다른 글
| 결정 트리 (분기 전후의 지니 불순도 감소량) (1) | 2025.08.15 |
|---|---|
| 일원분산분석 비교 (f_oneway vs anova_lm) (2) | 2025.08.15 |
| 정규성 검정 (2) | 2025.08.15 |
| SVM Hyper Parameters and Attributes (1) | 2025.08.14 |
| 선형회귀모형의 변수 선택 (후진제거법, 전진선택법) (1) | 2025.08.14 |




댓글