반응형
지니 불순도 정의는 다음과 같다.

분기 전후의 지니 불순도 감소량은 다음과 같다.
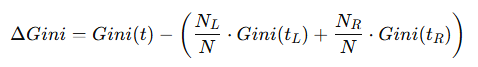
위 공식을 이용하여 아래 데이터에 대해 첫 번째 분기 전후의 지니 불순도 감소량을 구하라.
import pandas as pd
import numpy as np
np.random.seed(1234)
df = pd.DataFrame({
'feature1': np.random.normal(0, 1, 100),
'feature2': np.random.normal(50, 20, 100),
'target': np.random.choice([0, 1], size=100)
})
X = df[['feature1', 'feature2']]
y = df['target']
df.head()
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(random_state=1234, max_depth=4)
model.fit(X, y)DecisionTreeClassifier의 tree_ 속성을 이용하면 분기 전후의 불순도 감소량을 구할 수 있다.
tree.value[i]는 i번째 노드의 샘플 분포가 된다.
for i in range(model.tree_.node_count):
print(model.tree_.value[i], model.tree_.impurity[i])
위의 경우 0번째 샘플은 55, 45로 나뉘어지고 지니 불순도 정의에 의해 0.495임을 알 수 있다.
1 - (55 / 100) ** 2 - (45 / 100) ** 2
최초에 클래스 0이 55개, 1이 45개로 분기가 시작된다.
df['target'].value_counts()
[55, 45] → [5, 0] + [50, 45]
루트의 왼쪽 끝 노드는 [5, 0]으로 완전 순수하게 분류가 완료되었고,
루트의 오른쪽 끝 노드는 [50, 45]로 분류가 되는 것을 알 수 있다.
(이후 [50, 45] → [40, 42] + [10, 3])
root_node의 번호는 0이기 때문에 tree의 속성을 이용해 아래와 같이 지니 불순도 감소량을 구할 수 있다.
children_left / right [node] → 왼쪽 / 오른쪽 노드 번호 획득
impurity[node] → 해당 노드의 불순도
n_node_samples[node] → 해당 노드의 샘플 개수
# 지니 불순도 감소량
tree_ = model.tree_
# 노드 정보
root_node = 0
left_child = tree_.children_left[root_node]
right_child = tree_.children_right[root_node]
# 노드별 impurity
impurity_root = tree_.impurity[root_node]
impurity_left = tree_.impurity[left_child]
impurity_right = tree_.impurity[right_child]
# 노드별 sample 수
n_root = tree_.n_node_samples[root_node]
n_left = tree_.n_node_samples[left_child]
n_right = tree_.n_node_samples[right_child]
# 지니 불순도 감소량 계산
weighted_impurity = (n_left / n_root) * impurity_left + (n_right / n_root) * impurity_right
gini_decrease = impurity_root - weighted_impurity
# 출력
print(f"Root impurity: {impurity_root:.4f}")
print(f"Left impurity: {impurity_left:.4f}, samples: {n_left}")
print(f"Right impurity: {impurity_right:.4f}, samples: {n_right}")
print(f"Impurity decrease after split: {gini_decrease:.4f}")
반응형
'개발 > Python' 카테고리의 다른 글
| 결정 트리 (부스팅) (3) | 2025.08.15 |
|---|---|
| statsmodels ols 결과 출력하기 (1) | 2025.08.15 |
| 일원분산분석 비교 (f_oneway vs anova_lm) (2) | 2025.08.15 |
| 데이터 범주화, 구간화 (1) | 2025.08.15 |
| 정규성 검정 (2) | 2025.08.15 |




댓글