반응형
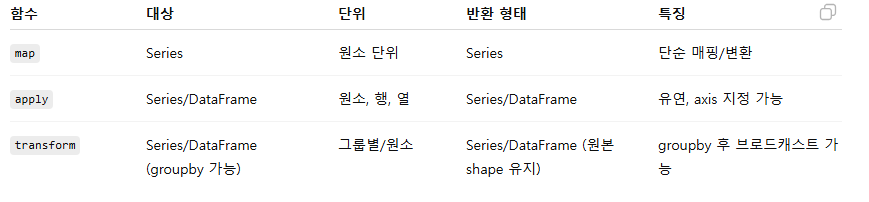
map
사용 대상 : Series
용도: 각 원소를 함수 적용 또는 매핑으로 변환
특징
- 함수 적용 가능 (lambda x: x**2)
- dict나 Series로 매핑 가능
- 매핑 대상에 없는 값은 NaN 처리
import pandas as pd
import pandas as np
df = pd.DataFrame({
'group': ['A','A','B','B'],
'value': [10, 20, 30, 40]
})
df['group'].map({'A':'a'})
'''
0 a
1 a
2 NaN
3 NaN
Name: group, dtype: object
'''
참고 (vs replace)
- 값 그대로 치환, 없으면 원래 값 유지, regex 지원
df['group'].replace({'A':'a'})
'''
0 a
1 a
2 B
3 B
Name: group, dtype: object
'''apply
사용 대상 : Series 또는 DataFrame
기능 : 각 원소, 행(row), 열(column)에 함수 적용 가능
반환 형태 : Series 또는 DataFrame
특징
- 더 유연, axis 지정 가능 (DataFrame의 경우)
행 / 열 별로 데이터 처리
import pandas as pd
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [10, 20, 30]
})
# 열 단위 합
df.apply(sum, axis=0)
# A 6
# B 60
# dtype: int64
# 행 단위 합
df.apply(sum, axis=1)
# 0 11
# 1 22
# 2 33
# dtype: int64
# element-wise
df['A'].apply(lambda x: x**2)
# 0 1
# 1 4
# 2 9
# dtype: int64
# keyword argument
df[['A', 'B']].apply(lambda x, y: x < y, y=5)
# A B
# 0 True False
# 1 True False
# 2 True False
apply로 2개의 컬럼 추가하기
import pandas as pd
df = pd.DataFrame({
'a': [1, 2, 3],
'b': [10, 20, 30]
})
def make_new_cols(row, k):
return pd.Series({'sum': row['a'] + row['b'] + k, 'diff': row['b'] - row['a'] + k})
df[['sum', 'diff']] = df.apply(lambda row: make_new_cols(row, k=5), axis=1)
df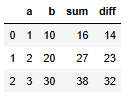
* applymap : 각 셀에 동일 연산을 적용 (ex. df.applymap(str) : 모든 값을 문자열로 변환)
transform
사용 대상 : Series 또는 DataFrame, 주로 groupby 후
기능 : 원본의 인덱스/행 수 유지하면서 값 변환
반환 형태 : Series 또는 DataFrame (원본 shape 유지)
특징
- 그룹별 연산 후 원래 구조 유지 가능 → groupby + apply와 달리 브로드캐스트 가능
df = pd.DataFrame({
'group': ['A','A','B','B'],
'value': [10, 20, 30, 40]
})
# 그룹별 평균을 각 행에 적용
df['group_mean'] = df.groupby('group')['value'].transform('mean')
# group value group_mean
# 0 A 10 15.0
# 1 A 20 15.0
# 2 B 30 35.0
# 3 B 40 35.0
# apply는 broadcast 불가
# df.groupby('group')['value'].apply(lambda x : x.mean())
# group
# A 15.0
# B 35.0
그룹별 unique한 컬럼 개수 구하기
import pandas as pd
import numpy as np
# 랜덤 시드 고정 (재현 가능)
np.random.seed(42)
# 데이터 생성
df = pd.DataFrame({
'group': np.random.choice(['A', 'B', 'C'], size=30),
'age': np.random.randint(10, 15, size=30)
})
df.groupby('group')['age'].nunique()
'''
group
A 3
B 4
C 5
'''
df.groupby('group')['age'].transform("nunique")
그룹별 unique한 컬럼 개수 구하기 (결측치도 값으로 처리하기)
import pandas as pd
df = pd.DataFrame({
"category": ["A", "A", "A", "B", "B", "B", "C"],
"value": [1, 1, None, 2, None, 3, None]
})
df["unique_count_no_na"]
= df.groupby("category")["value"].transform(lambda x: x.nunique(dropna=False))
df
반응형
'개발 > Python' 카테고리의 다른 글
| shift, rolling (0) | 2025.10.26 |
|---|---|
| melt, stack, unstack (0) | 2025.10.26 |
| 라벨 스무딩 (Label Smoothing) (0) | 2025.10.25 |
| 가설검정 (0) | 2025.10.25 |
| 마할라노비스 거리 (0) | 2025.10.25 |
댓글