반응형

전체 예시
import pandas as pd
# 예시 데이터 (wide 형태)
df = pd.DataFrame({
'name': ['A', 'B', 'C'],
'math': [80, 90, 85],
'english': [70, 88, 95],
'science': [75, 85, 90]
})
print("원본 (wide 형태):\n", df, "\n")
# melt (wide → long)
df_melt = pd.melt(df, id_vars='name', var_name='subject', value_name='score')
print("melt 결과:\n", df_melt, "\n")
# stack / unstack 비교 위해 MultiIndex로 변환
df_multi = df.set_index('name')
stacked = df_multi.stack()
print("stack 결과:\n", stacked, "\n")
unstacked = stacked.unstack()
print("unstack 결과:\n", unstacked, "\n")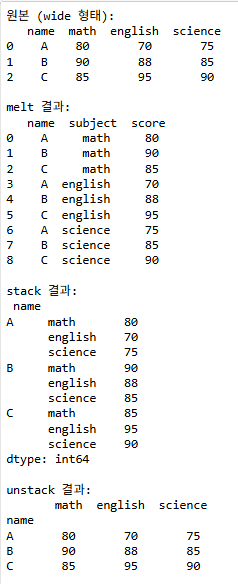
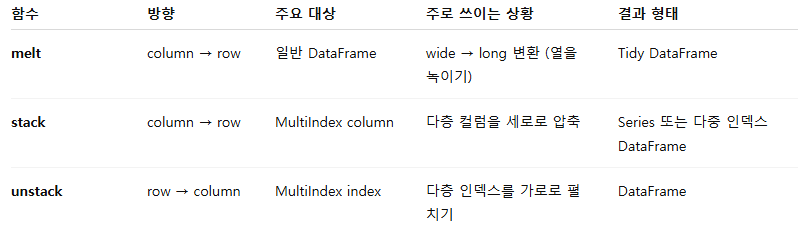
melt - wide → long (컬럼을 행으로)
특징
- 여러 열(column)을 하나의 열로 녹이는 형태.
- "피벗 해제" (즉, pivot의 반대).
사용 상황
- 엑셀처럼 열마다 "year", "month" 등이 있는 데이터를 "tidy data" 형태(하나의 변수=column)로 바꾸고 싶을 때
pd.melt(df,
id_vars=['고정컬럼'], value_vars=['녹일컬럼들'], var_name='새컬럼', value_name='값컬럼'
)
예시
- name을 고정
- value_vars가 생략 → id_vars를 제외한 모든 열을 melt
- 새로운 컬럼의 이름을 subject로
- 값은 score
import pandas as pd
df = pd.DataFrame({
'name': ['A', 'B'],
'math': [80, 90],
'english': [70, 85]
})
print(df)
# name math english
# 0 A 80 70
# 1 B 90 85
melted = pd.melt(df, id_vars='name', var_name='subject', value_name='score')
print(melted)
# name subject score
# 0 A math 80
# 1 B math 90
# 2 A english 70
# 3 B english 85vs pivot_table

import pandas as pd
df = pd.DataFrame({
'name': ['A', 'B', 'C'],
'math': [80, 90, 85],
'english': [70, 88, 95]
})
print(df)
'''
name math english
0 A 80 70
1 B 90 88
2 C 85 95
'''
# wide → long (열을 녹임)
df_melt = pd.melt(df, id_vars='name', var_name='subject', value_name='score')
print(df_melt)
'''
name subject score
0 A math 80
1 B math 90
2 C math 85
3 A english 70
4 B english 88
5 C english 95
'''
# long → wide (열로 펼침 + 집계)
# 이제 위의 long 데이터를 다시 "wide"로 되돌림.
df_pivot = df_melt.pivot_table(index='name', columns='subject', values='score')
print(df_pivot)
'''
subject english math
name
A 70 80
B 88 90
C 95 85
'''stack - column → row (wide → long)
특징
- MultiIndex 컬럼 구조를 가지고 있을 때, 하위 레벨의 열 인덱스를 행으로 내림
- 결과적으로 Series나 다차원 인덱스 DataFrame이 됨
사용 상황
- 계층형 컬럼(MultiIndex column)을 세로 방향으로 "압축"하고 싶을 때
예시
- 'A', 'B'는 index
- 'math', 'eng'가 두 번째 인덱스로 내려감
→ 행 방향으로 열을 접는다
import pandas as pd
df = pd.DataFrame({
('score', 'math'): [80, 90],
('score', 'eng'): [70, 85]
}, index=['A', 'B'])
print(df)
# score
# math eng
# A 80 70
# B 90 85
stacked = df.stack()
print(stacked)
# score
# A math 80
# eng 70
# B math 90
# eng 85
# dtype: int64unstack - row → column (long → wide)
특징
- stack의 반대 동작
- 인덱스 레벨 중 하나를 열로 올림
사용 상황
- groupby 결과처럼 계층형 인덱스를 가진 데이터를 가로로 펼치고 싶을 때.
예시
import pandas as pd
df = pd.DataFrame({
('score', 'math'): [80, 90],
('score', 'eng'): [70, 85]
}, index=['A', 'B'])
print(df)
# score
# math eng
# A 80 70
# B 90 85
stacked = df.stack()
print(stacked)
# score
# A math 80
# eng 70
# B math 90
# eng 85
# dtype: int64
stacked.unstack()
# score
# math eng
# A 80 70
# B 90 85반응형
'개발 > Python' 카테고리의 다른 글
| Dictionary (0) | 2025.11.15 |
|---|---|
| shift, rolling (0) | 2025.10.26 |
| map, apply, transform (0) | 2025.10.25 |
| 라벨 스무딩 (Label Smoothing) (0) | 2025.10.25 |
| 가설검정 (0) | 2025.10.25 |

댓글