shift() - 행을 "밀기"
- 이전 / 다음 행의 값을 참조할 때 사용
예제 - 다음 행과의 날짜 차이 구하기
import pandas as pd
# 예시 데이터 생성
data = {
'date_str': ['2025-10-10', '2025-10-12', '2025-10-15', '2025-10-20']
}
df = pd.DataFrame(data)
# datetime 타입으로 변환
df['date'] = pd.to_datetime(df['date_str'])
# 다음 행과의 day 차이 계산
df['day_diff'] = df['date'] - df['date'].shift(1)
df['day_diff'] = df['day_diff'].dt.days # timedelta를 일(day)로 변환
df
참고 - 뒤집기
df[::-1]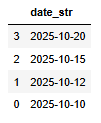
rolling() - 일정 구간 "창(window)"을 만들어 계산
- 이전 n개 구간의 평균, 합계, 표준편차 등 통계량을 구할 때 사용

custom 함수 사용 예시
- raw=True : numpy array로 전달 → 대부분 함수 작성이 편함
- raw=False : pandas Series로 전달 → index, name 사용 가능
import pandas as pd
import numpy as np
data = pd.Series([1, 2, 3, 4, 5, 6, 7, 8, 9])
def my_func(x):
return np.sum(x)
# rolling 적용 후 함수 사용
result = data.rolling(window=3).apply(my_func, raw=True)
result
예제 1
- 이전 5개의 구간의 평균, 합계, 표준편차
import pandas as pd
import numpy as np
# 예시 데이터 생성
np.random.seed(42)
data = np.random.randint(1, 100, size=15) # 1~100 사이 랜덤 정수 15개
dates = pd.date_range(start='2025-10-01', periods=15, freq='D') # 하루 단위 날짜
df = pd.DataFrame({
'date': dates,
'value': data
})
# 이전 5개 구간에 대한 rolling 통계
df['rolling_mean'] = df['value'].rolling(window=5).mean() # 평균
df['rolling_sum'] = df['value'].rolling(window=5).sum() # 합계
df['rolling_std'] = df['value'].rolling(window=5).std() # 표준편차
df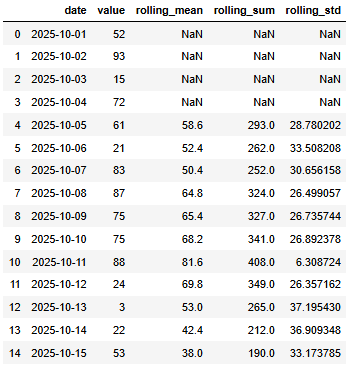
예제 2
- 이전 시간 (초, 분, 시)
- datetime을 인덱스로 설정
import pandas as pd
import numpy as np
np.random.seed(42)
# 1) 초 단위 데이터 (1초 간격, 20개)
dates_sec = pd.date_range(start='2025-10-26 10:00:00', periods=20, freq='S')
values_sec = np.random.randint(1, 100, size=20)
df_sec = pd.DataFrame({'datetime': dates_sec, 'value': values_sec})
df_sec.set_index('datetime', inplace=True)
df_sec['mean_5s'] = df_sec['value'].rolling('5S').mean()
df_sec['sum_5s'] = df_sec['value'].rolling('5S').sum()
df_sec['std_5s'] = df_sec['value'].rolling('5S').std()
# 2) 분 단위 데이터 (1분 간격, 20개)
dates_min = pd.date_range(start='2025-10-26 10:00:00', periods=20, freq='T')
values_min = np.random.randint(1, 100, size=20)
df_min = pd.DataFrame({'datetime': dates_min, 'value': values_min})
df_min.set_index('datetime', inplace=True)
df_min['mean_5min'] = df_min['value'].rolling('5T').mean()
df_min['sum_5min'] = df_min['value'].rolling('5T').sum()
df_min['std_5min'] = df_min['value'].rolling('5T').std()
# 3) 시간 단위 데이터 (1시간 간격, 20개)
dates_hour = pd.date_range(start='2025-10-26 00:00:00', periods=20, freq='H')
values_hour = np.random.randint(1, 100, size=20)
df_hour = pd.DataFrame({'datetime': dates_hour, 'value': values_hour})
df_hour.set_index('datetime', inplace=True)
df_hour['mean_1h'] = df_hour['value'].rolling('1H').mean()
df_hour['sum_1h'] = df_hour['value'].rolling('1H').sum()
df_hour['std_1h'] = df_hour['value'].rolling('1H').std()
# 출력 확인
print("=== 초 단위 rolling ===")
print(df_sec)
print("\n=== 분 단위 rolling ===")
print(df_min)
print("\n=== 시간 단위 rolling ===")
print(df_hour)
=== 초 단위 rolling ===
value mean_5s sum_5s std_5s
datetime
2025-10-26 10:00:00 52 52.000000 52.0 NaN
2025-10-26 10:00:01 93 72.500000 145.0 28.991378
2025-10-26 10:00:02 15 53.333333 160.0 39.017090
2025-10-26 10:00:03 72 58.000000 232.0 33.196385
2025-10-26 10:00:04 61 58.600000 293.0 28.780202
2025-10-26 10:00:05 21 52.400000 262.0 33.508208
2025-10-26 10:00:06 83 50.400000 252.0 30.656158
2025-10-26 10:00:07 87 64.800000 324.0 26.499057
2025-10-26 10:00:08 75 65.400000 327.0 26.735744
2025-10-26 10:00:09 75 68.200000 341.0 26.892378
2025-10-26 10:00:10 88 81.600000 408.0 6.308724
2025-10-26 10:00:11 24 69.800000 349.0 26.357162
2025-10-26 10:00:12 3 53.000000 265.0 37.195430
2025-10-26 10:00:13 22 42.400000 212.0 36.909348
2025-10-26 10:00:14 53 38.000000 190.0 33.173785
2025-10-26 10:00:15 2 20.800000 104.0 20.729206
2025-10-26 10:00:16 88 33.600000 168.0 36.760033
2025-10-26 10:00:17 30 39.000000 195.0 32.924155
2025-10-26 10:00:18 38 42.200000 211.0 31.610125
2025-10-26 10:00:19 2 32.000000 160.0 35.270384
=== 분 단위 rolling ===
value mean_5min sum_5min std_5min
datetime
2025-10-26 10:00:00 64 64.000000 64.0 NaN
2025-10-26 10:01:00 60 62.000000 124.0 2.828427
2025-10-26 10:02:00 21 48.333333 145.0 23.755701
2025-10-26 10:03:00 33 44.500000 178.0 20.856654
2025-10-26 10:04:00 76 50.800000 254.0 22.906331
2025-10-26 10:05:00 58 49.600000 248.0 22.187835
2025-10-26 10:06:00 22 42.000000 210.0 24.155745
2025-10-26 10:07:00 89 55.600000 278.0 28.183328
2025-10-26 10:08:00 49 58.800000 294.0 25.781777
2025-10-26 10:09:00 91 61.800000 309.0 28.960318
2025-10-26 10:10:00 59 62.000000 310.0 28.930952
2025-10-26 10:11:00 42 66.000000 330.0 22.737634
2025-10-26 10:12:00 92 66.600000 333.0 23.522330
2025-10-26 10:13:00 60 68.800000 344.0 21.924872
2025-10-26 10:14:00 80 66.600000 333.0 19.565275
2025-10-26 10:15:00 15 57.800000 289.0 30.613722
2025-10-26 10:16:00 62 61.800000 309.0 29.312114
2025-10-26 10:17:00 62 55.800000 279.0 24.211567
2025-10-26 10:18:00 47 53.200000 266.0 24.345431
2025-10-26 10:19:00 62 49.600000 248.0 20.403431
=== 시간 단위 rolling ===
value mean_1h sum_1h std_1h
datetime
2025-10-26 00:00:00 51 51.0 51.0 NaN
2025-10-26 01:00:00 55 55.0 55.0 NaN
2025-10-26 02:00:00 64 64.0 64.0 NaN
2025-10-26 03:00:00 3 3.0 3.0 NaN
2025-10-26 04:00:00 51 51.0 51.0 NaN
2025-10-26 05:00:00 7 7.0 7.0 NaN
2025-10-26 06:00:00 21 21.0 21.0 NaN
2025-10-26 07:00:00 73 73.0 73.0 NaN
2025-10-26 08:00:00 39 39.0 39.0 NaN
2025-10-26 09:00:00 18 18.0 18.0 NaN
2025-10-26 10:00:00 4 4.0 4.0 NaN
2025-10-26 11:00:00 89 89.0 89.0 NaN
2025-10-26 12:00:00 60 60.0 60.0 NaN
2025-10-26 13:00:00 14 14.0 14.0 NaN
2025-10-26 14:00:00 9 9.0 9.0 NaN
2025-10-26 15:00:00 90 90.0 90.0 NaN
2025-10-26 16:00:00 53 53.0 53.0 NaN
2025-10-26 17:00:00 2 2.0 2.0 NaN
2025-10-26 18:00:00 84 84.0 84.0 NaN
2025-10-26 19:00:00 92 92.0 92.0 NaN예제 3
- 이전 날짜 (년, 월, 일)
- datetime을 인덱스로 설정
import pandas as pd
import numpy as np
np.random.seed(42)
# 예제 날짜 (연속적이지 않음)
dates = pd.to_datetime([
'2025-01-05', '2025-01-20', '2025-02-03', '2025-02-18',
'2025-03-01', '2025-04-10', '2025-06-05', '2025-09-15',
'2025-12-25'
])
values = np.random.randint(10, 100, size=len(dates))
df = pd.DataFrame({
'date': dates,
'value': values
})
# datetime을 인덱스로 설정
df.set_index('date', inplace=True)
# --- 이전 30일(D) 구간 통계 ---
df['mean_30D'] = df['value'].rolling('30D').mean()
df['sum_30D'] = df['value'].rolling('30D').sum()
df['std_30D'] = df['value'].rolling('30D').std()
# --- 이전 2개월(M) 구간 통계 ---
df['mean_2M'] = df['value'].rolling('62D').mean() # 월 단위는 평균 31일 기준
df['sum_2M'] = df['value'].rolling('62D').sum()
df['std_2M'] = df['value'].rolling('62D').std()
# --- 이전 1년(Y) 구간 통계 ---
df['mean_1Y'] = df['value'].rolling('365D').mean()
df['sum_1Y'] = df['value'].rolling('365D').sum()
df['std_1Y'] = df['value'].rolling('365D').std()
df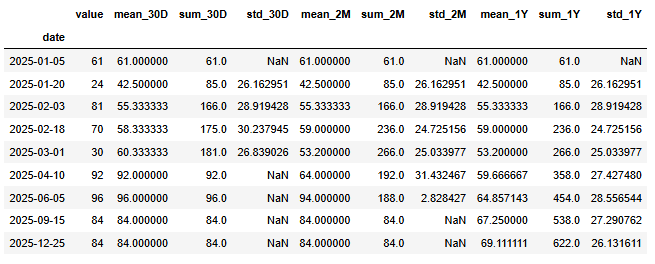
min_periods
- min_periods는 rolling에서 최소 데이터 개수 기준을 설정할 때 사용하는 옵션
rolling(window=N, min_periods=M)
- window=N : 이동 구간 크기
- min_periods=M : 구간 안에서 최소 M개의 값이 있어야 계산
- 기본값 : min_periods=None → window 크기와 동일 (즉, 구간에 값이 부족하면 NaN)
- 값이 충분하지 않으면 계산하지 않고 NaN 반환
예를 들어, window=5인데 첫 3개의 값밖에 없으면
- min_periods=5 → NaN
- min_periods=1 → 평균, 합계 계산
import pandas as pd
import numpy as np
np.random.seed(42)
# 띄엄띄엄 날짜 데이터
dates = pd.to_datetime([
'2025-10-01', '2025-10-03', '2025-10-04',
'2025-10-05', '2025-10-10', '2025-10-11',
'2025-10-15', '2025-10-20'
])
values = [10, 20, 30, 40, 50, 60, 70, 80]
df = pd.DataFrame({
'datetime': dates,
'value': values
})
# datetime을 인덱스로 설정
df.set_index('datetime', inplace=True)
df['sum_3'] = df['value'].rolling(3).sum()
# 이전 데이터가 2개 이상이면 합
df['sum_3_min'] = df['value'].rolling(3, min_periods=2).sum()
df['sum_3D'] = df['value'].rolling('3D').sum()
df['sum_3D_min'] = df['value'].rolling('3D', min_periods=2).sum()
df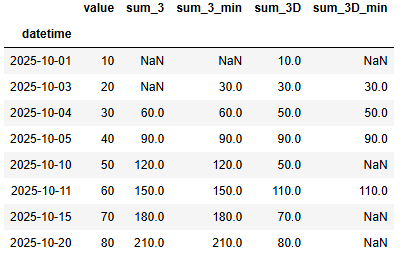
이후의 행 처리
- roliling에서 지원하지 않음.
- 따라서 직접 계산
다음 2개의 행의 합
import pandas as pd
# 예시 데이터
df = pd.DataFrame({'value': [10, 20, 30, 40, 50]})
N = 2 # 다음 2개 행 합
# 방법 1: shift와 sum
# 현재 행 이후 2개의 합
df['next_N_sum'] = df['value'].shift(-1).fillna(0) + df['value'].shift(-2).fillna(0)
print(df)
'''
value next_N_sum
0 10 50.0 # 20 + 30
1 20 70.0 # 30 + 40
2 30 90.0 # 40 + 50
3 40 50.0 # 50 + 0
4 50 0.0 # 다음 값 없음
'''
apply로 이후 7일 구간의 합 계산
import pandas as pd
import numpy as np
dates = pd.to_datetime([
'2025-10-01', '2025-10-03', '2025-10-04', '2025-10-07', '2025-10-10'
])
values = [10, 20, 30, 40, 50]
df = pd.DataFrame({'datetime': dates, 'value': values})
df.set_index('datetime', inplace=True)
# lambda로 이후 7일 구간 합계 계산
df['sum_7D_future'] = df.index.to_series().apply(
lambda x: df.loc[(df.index > x) & (df.index <= x + pd.Timedelta(days=7)), 'value'].sum()
)
df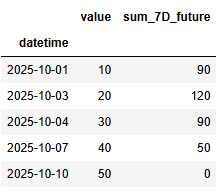
'개발 > Python' 카테고리의 다른 글
| 불편추정량 (Unbiased Estimator) (0) | 2025.11.15 |
|---|---|
| Dictionary (0) | 2025.11.15 |
| melt, stack, unstack (0) | 2025.10.26 |
| map, apply, transform (0) | 2025.10.25 |
| 라벨 스무딩 (Label Smoothing) (0) | 2025.10.25 |


댓글