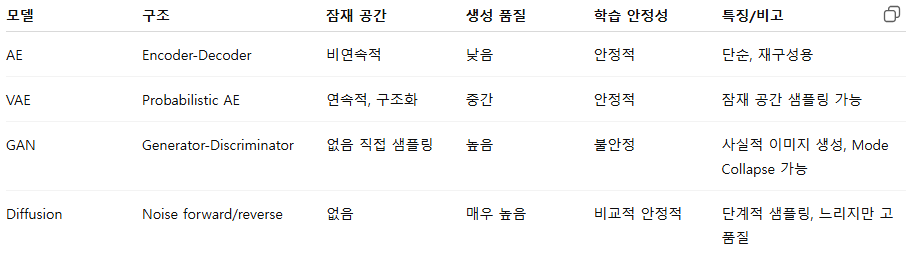
AutoEncoder (AE)
- 입력 이미지를 압축(latent space)하고 다시 복원하는 자가 지도 학습 모델
- 데이터의 레이블이 없는 상태에서 입력 데이터의 특징을 추출
- 데이터 압축, 차원 축소, 노이즈 제거, 이상 탐지, 데이터 생성에 사용
- 목표 : 입력과 출력 이미지의 재구성 손실(reconstruction loss) 최소화
- 입력 데이터에 노이즈를 주고, 노이즈가 없는 상태를 출력하도록 학습 (→ 노이즈 캔슬링에 응용)
구조
- Encoder → Latent Vector → Decoder
- 인코더는 점점 유닛을 줄여 병목층을 형성, 디코더는 원래 데이터 형태에 맞게 층의 유닛을 늘림.

장점
- 구조가 단순하고 구현 용이
- 차원 축소, 특징 추출, 노이즈 제거(denoising) 등에 활용 가능
단점
- 생성 모델로서 품질이 낮음 → 출력이 흐릿하거나 디테일 부족
- 잠재 공간(latent space)이 구조화되어 있지 않아 샘플링이 어려움
- Latent space 크기 제한이 없을 경우 Identity Mapping 문제 발생 가능
* Identity Mapping Problem : "입력 = 출력"만 달성하려고 하면서 아무런 의미 있는 특징을 학습하지 않는 문제
학습 안정화 방법
- 일반적으로 MSE, L1, SSIM 등의 손실 함수 사용
- Batch Normalization, Dropout 등 일반적인 학습 안정화 기법 적용
Variational AutoEncoder (VAE)
- AE의 확률적 확장
- Encoder가 입력을 잠재 분포(latent distribution)로 매핑 → Decoder가 샘플링된 latent로 이미지 생성
- 이미지 생성, 데이터 보간, 노이즈 제거, 이상 탐지에 사용
- 확률적 특성으로 미분이 어려움 → 재매개변수화 트릭 사용
- 손실 함수: 재구성 손실 + KL divergence

장점
- 잠재 공간이 연속적이고 구조화되어 있음 → 새로운 샘플 생성 가능
- 안정적 학습 (재구성 품질이 GAN보다 떨어질 수 있음)
- Mode Collapse 문제가 적음 (GAN 대비)
단점
- 생성 이미지가 다소 흐림
- 복잡한 분포 학습 시 디테일이 부족
- KL term이 지나치게 크면 Posterior Collapse 발생 가능
* Posterior Collapse : 사후분포 붕괴, Encoder가 아무 의미도 없는 잠재 분포를 학습해버리는 현상
ㄴ latent vector가 입력 데이터와 상관없이 특정 고정 분포(예: N(0, I))로 수렴
학습 안정화 방법
- KL divergence와 reconstruction loss의 가중치 조절 (β-VAE)
- Encoder/Decoder 구조 최적화, BatchNorm 사용
Generative Adversarial Networks (GAN)
- 적대적 학습(adversarial training) 기반 생성 모델
- 구조 : Generator vs Discriminator
- 목표 : Generator는 현실같은 이미지를 생성하고, Discriminator는 가짜 / 진짜를 구분
- Generator는 실제 이미지를 입력 받지 않고, 점진적으로 그럴듯한 가짜 이미지를 만드는 법을 배운다.
- Generator의 입력은 Discriminator를 통해 전달되는 그레디언트

장점
- 고품질, 사실적인 이미지 생성 가능
- 다양한 변형: DCGAN, StyleGAN, CycleGAN 등
단점
- 학습 불안정, Mode Collapse 문제 (Adam, RMSProp)
- Hyperparameter와 구조 설계에 민감
학습 안정화 방법
- Wasserstein GAN (WGAN) → 학습 안정화 및 Mode Collapse 완화
- Gradient Penalty 적용 (WGAN-GP)
- Label smoothing, Spectral Normalization
- Generator와 Discriminator 학습 균형 조절, 배치 정규화 (생성자 출력 층, 판별자 입력 층 제외)
- Generator 풀링 층을 전치 합성곱으로, Discriminator의 합성 곱을 스트라이드 합성곱으로 교체
- 깊은 층을 위해 쌓은 완전 연결 은닉 층 제거
- 출력층만 tanh 함수 사용, 그 외 Generator는 ReLU 함수 사용
- DiscriminatorDML의 모든 층은 LeakyReLU 사용
Diffusion Model
- 점진적 노이즈 추가 → 노이즈 제거 과정으로 이미지 생성
- Forward process: 이미지를 점진적으로 Gaussian noise로 변환
- Reverse process: 학습된 모델로 노이즈를 제거하며 샘플 생성

장점
- 매우 고품질 이미지 생성
- GAN보다 Mode Collapse 없음 (더 쉬운 훈련)
- 텍스트 조건부 생성 가능 (예: Stable Diffusion, DALL·E2)
단점
- 역방향 확산 과정에서 샘플링 속도가 느림 (수백~수천 단계 필요)
- 학습 비용이 매우 높음
학습 안정화 방법
- Noise schedule 조정
- Variance scheduling, Classifier-free guidance
- Stable optimization (AdamW, gradient clipping 등)
학습 안정화 vs 과대적합
→ 학습 안정화는 학습 과정의 문제이고, 과대적합은 학습 결과(성능)의 문제
학습 안정화 (Stable Training)
- 모델이 학습 과정에서 불안정하지 않고 안정적으로 수렴하도록 만드는 것
- 주로 GAN 같은 경쟁적/복잡한 모델에서 강조됨
특징
- Gradient가 잘 흐르고 폭발/소실이 없음
- Loss가 발산하지 않고 점진적으로 수렴
- Generator와 Discriminator가 균형 잡힌 경쟁
- 모드 붕괴(Mode Collapse)가 최소화
목적
- 학습 과정 자체를 안정화
- 모델이 올바르게 학습하도록 보장
과대적합 (Overfitting)
- 모델이 학습 데이터에 너무 치중하여 훈련 데이터만 잘 맞고, 새로운 데이터에는 성능이 떨어지는 현상
특징
- Train loss는 매우 낮지만 Test loss는 높음
- 모델이 데이터의 노이즈까지 학습 → 일반화 성능 저하
- 복잡한 모델, 작은 데이터셋에서 자주 발생
목적
- 모델이 훈련 데이터에만 최적화되지 않도록 일반화
- 데이터 증강, 정규화, Dropout 등으로 완화 가능

'개발 > Python' 카테고리의 다른 글
| Batch Normalization vs Layer Normalization (0) | 2025.10.08 |
|---|---|
| 과대적합 해결 방법 (0) | 2025.10.08 |
| 주요 합성곱 신경망 (0) | 2025.10.06 |
| 경사 하강법, 옵티마이저 (0) | 2025.10.06 |
| 활성화 함수 (0) | 2025.10.06 |




댓글