경사 하강법 (Gradient Descent)
- 딥러닝 모델의 손실(loss)을 최소화하기 위해 가중치를 조금씩 조정하는 최적화 알고리즘
- 손실 함수(예측값과 실제값의 차이)를 최소화하는 가중치 값을 찾는 것
- 표준화, 정규화는 각 피처의 스케일을 맞춰 경사 하강이 더 안정적이고 빠르게 수렴하도록 도와줌
ex)

# loss 함수 = f(x) = x^4 - x^3 - 2x^2 + 12x + 5
# 초기값이 x = 1일 때, Gradient Descent 방법을 2번 적용한 후의 x는?
# 학습률은 0.5
# 함수 f(x)의 도함수 정의
def grad_f(x):
return 4*x**3 - 3*x**2 - 4*x + 12
# 초기값과 학습률
x = 1
learning_rate = 0.5
# Gradient Descent 2회 수행
for i in range(2):
gradient = grad_f(x)
x = x - learning_rate * gradient
print(f"Step {i+1}: x = {x}")
print(f"\n최종 x 값: {x}") # 87.625
# 1 - 0.5 * (grad_f(1) = 9) = -3.5
# -3.5 - 0.5 * (grad_f(-3.5) = -182.25)Vanishing Gradient (기울기 소실)
- 신경망을 깊게 쌓았을 때, 역전파 과정에서 기울기가 점점 작아져 0에 가까워지는 현상을 말합니다.
- 결과적으로 초기 층(입력층 근처) 가중치가 거의 업데이트되지 않아 학습이 거의 이루어지지 않음.

원인
- 활성화 함수의 미분값이 1보다 작을 때, 여러 층을 거치며 곱해지면서 기울기가 점점 작아짐.
- ex) Sigmoid 함수 → 미분값 최대 0.25
- tanh 함수 → 미분값 최대 1, 하지만 대부분 0~1 구간
- 층이 깊으면 깊을수록 기울기가 0으로 수렴.
대응법
ReLU 계열 활성화 함수 사용
- ReLU, Leaky ReLU, GELU 등은 미분값이 0~1로 제한되지 않아 기울기가 소실되는 문제 완화
He 초기화 (He initialization)
- ReLU와 잘 맞는 가중치 초기화
Batch Normalization
- 각 층의 입력 분포를 정규화해 기울기 소실 완화
Residual / Skip Connection
- ResNet처럼 입력을 다음 층에 직접 더해주는 구조로 기울기 전달이 쉬워짐
- 네트워크의 하위 노드의 출력값을 상위 노드에 전달해주는 잔차 연결 사용
LSTM
- 긴 시퀀스에서는 여전히 한계
보조 분류기 배치 (Auxillary Classifier)
- 네트워크 증강에 학습 과정만에 추가
- GoogLeNet의 중간 층에서 학습 안정성

Exploding Gradient (기울기 폭발)
- 역전파 과정에서 기울기 값이 매우 커져서 가중치가 급격히 발산하는 현상.
- 학습이 불안정해지고, 손실값이 NaN이 되거나 발산할 수 있음.
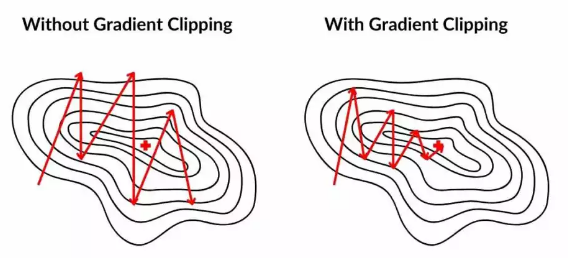
원인
- 가중치가 크거나, 활성화 함수/손실 함수에서 미분값이 1보다 큰 경우.
- 여러 층을 거치면서 기울기가 기하급수적으로 커짐.
- RNN / LSTM 같이 시간축으로 긴 역전파를 수행하는 모델에서 현상이 더 자주 발생
대응법
Gradient Clipping
- 기울기의 L2 norm을 일정 임계값으로 제한.
적절한 가중치 초기화
- Xavier/Glorot 초기화: 시그모이드 계열에서 폭발 방지
- He 초기화: ReLU 계열에서 폭발 방지
학습률 조정
- 너무 크면 폭발 가능성 ↑ → 학습률 감소
Batch Normalization
- 입력 분포를 정규화하여 기울기 폭발 방지
Residual / Skip Connection
- 깊은 네트워크에서도 안정적인 기울기 흐름 유지
적절한 활성화 함수 선택 (예: ReLU 계열)
- Sigmoid는 작은 구간에서 미분이 커질 수 있어 불안정

배치 경사 하강법 (Batch Gradient Descent)
- 전체 데이터(전부)를 사용해서 손실의 기울기를 계산하고 한 번 업데이트하는 방식.
장점
- 전체 데이터를 기준으로 계산 → 수렴이 안정적이고 정확함
- 볼록(convex) 문제에서는 최적점으로 수렴
단점
- 데이터가 크면 계산량 매우 큼 → 속도 느림, 메모리 많이 필요
- 실시간 학습 불가능
확률적 경사 하강법 (Stochastic Gradient Descent, SGD)
- 데이터 하나(샘플 1개)를 랜덤하게 선택해서 매번 업데이트.
- 각 Batch가 전체 데이터를 잘 대표할수록 성능 향상 (ex. 정렬된 데이터라면 정렬의 편향성 때문에 성능 감소)
- 데이터 순서를 에포크마다 무작위로 섞는(Shuffle) 작업이 중요
장점
- 빠름, 실시간 업데이트 가능
- 지역 최소값(local minima)에 덜 빠짐 (계산이 요동치기 때문)
단점
- 손실 값이 많이 요동해서 불안정
- 최적점 근처에서 수렴하지 못하고 출렁일 수 있음
- 비등방성 함수(방향에 따라 기울기가 달라지는 함수)에서 탐색 경로가 비효율적
미니 배치 경사 하강법 (Mini-Batch Gradient Descent)
- 전체 데이터 중 일부(예: 32개, 64개 등)를 묶은 "미니배치" 단위로 기울기 계산 후 업데이트.
- 배치 크기가 전체 데이터라면 배치 경사 하강법, 배치 크기가 1이라면 확률적 경사 하강법
- 일반적으로 32~256 배치 크기에서 가장 좋은 효율을 보임
장점
- 속도와 안정성의 균형
- GPU 병렬 처리 가능 → 딥러닝에서 가장 많이 사용
- 수렴도 비교적 안정적
단점
- 배치 크기에 따라 성능 차이 발생
- 너무 작으면 SGD처럼 불안정, 너무 크면 느려짐

오차 역전파 (Backpropagation)
- 신경망에서 학습을 위해 가중치를 업데이트하는 방법
- 오차(손실)의 기울기가 어떻게 각 가중치에 영향을 주는지 계산하는 알고리즘
- 계산된 손실의 그레이던트를 출력층에서 거꾸로 입력층으로 이전 단계의 그레디언트를 바탕으로 다음 단계 그레디언트를 구함
- 효율적 학습 → 모든 가중치에 대한 gradient를 한 번의 순전파/역전파로 계산 가능
- 경사 하강법을 통해 신경망 학습
- 체인 법칙 이용
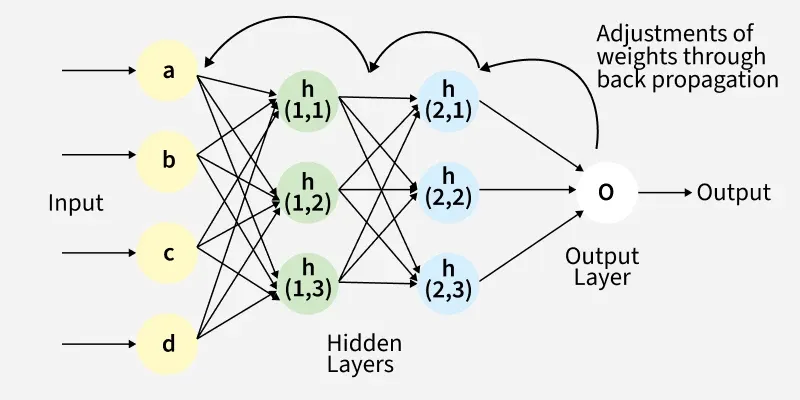
순전파 (Forward Propagation)
- 인공 신경망에서 입력 데이터를 받아 출력 결과를 계산하는 과정
- 신경망이 학습 중에 주어진 입력 데이터에 대해 어떤 예측을 도출하는지 결정되는 과정
- 입력층을 통해 뉴런에 전달된 데이터는 각 입력별로 가중치가 곱해짐
- 가중치가 곱해진 특성 값 + 편향 + 비선형 활성화 함수
- 활성화 함수는 신경망이 복잡한(비선형적인) 데이터 패턴을 학습할 수 있도록 함
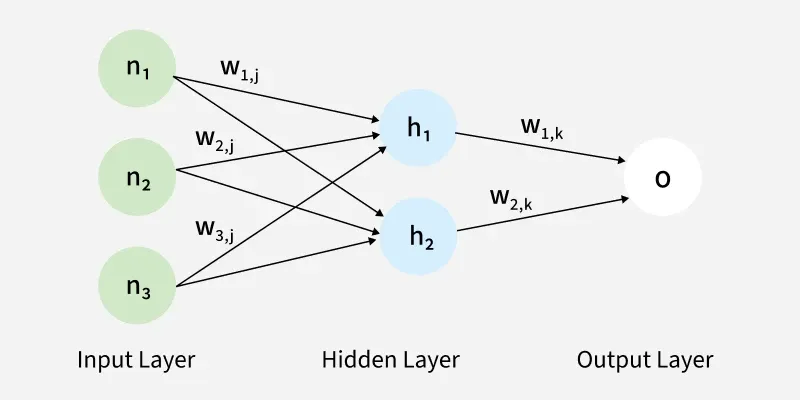
→ 순전파는 예측값을 계산하는 과정이고, 역전파는 그 예측 오차를 이용해 가중치를 업데이트하는 과정이다.
옵티마이저

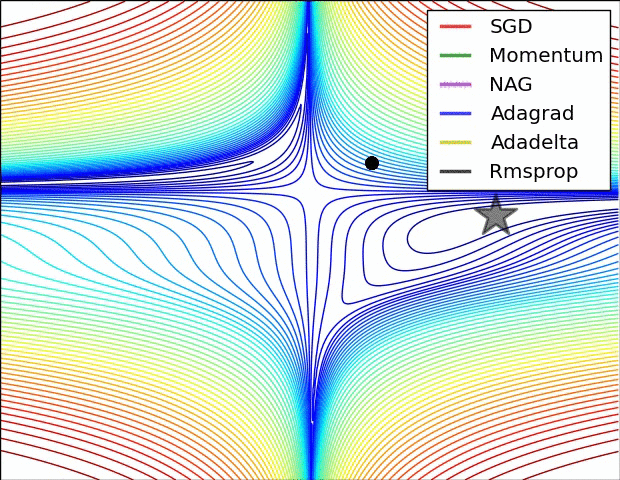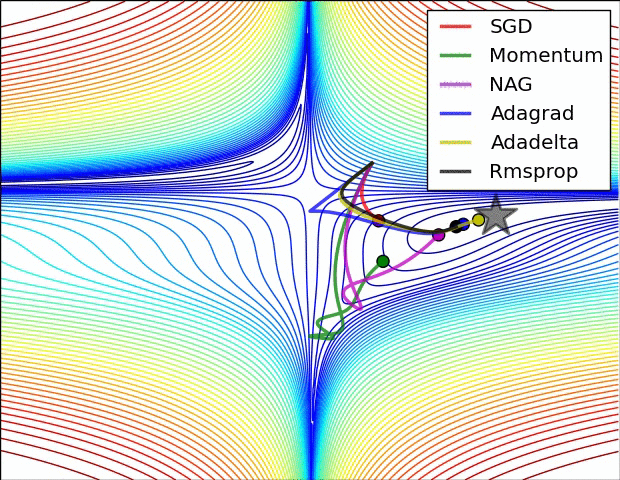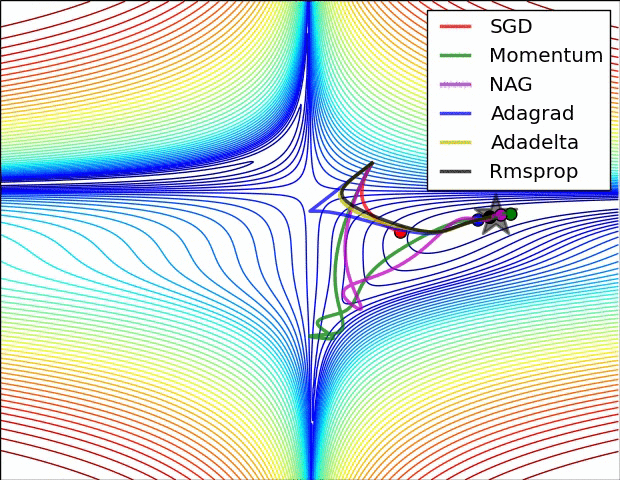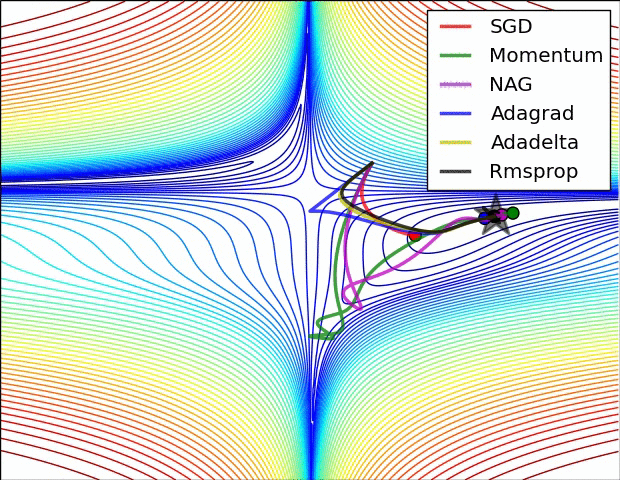
모멘텀 (Momentum)
- 이전 기울기 방향을 "관성(velocity)"처럼 누적해서 가속하는 방식.
- 즉, 경사를 따라 굴러가는 쇠구슬처럼 움직임.
장점
- 수렴 속도 향상
- 지그재그 감소 (특히 좁고 긴 골짜기 형태)
단점
- 관성이 너무 크면 최적점을 지나칠 수 있음
- 학습률 튜닝 필요
NAG (Nesterov Accelerated Gradient)
- 모멘텀의 "다음 위치"를 미리 예상하고 그 지점에서 기울기를 계산.
장점
- 모멘텀보다 수렴이 더 빠르고 정교함 (과도한 움직임 방지)
- overshooting(오버슈팅) 감소
단점
- 구현과 계산이 약간 더 복잡
AdaGrad
- 매개변수마다 다른 학습률을 적용.
- 많이 업데이트된 파라미터는 학습률을 줄이고, 적게 업데이트된 파라미터는 학습률을 크게 유지.
장점
- 희소 데이터(sparse data)에 강함
- 자동으로 학습률 조정
단점
- 시간이 지날수록 학습률이 0에 가까워져 학습이 멈춤
RMSProp
- AdaGrad의 학습률 감소 문제를 해결.
- 기울기의 제곱을 "지수이동평균"으로 누적해 최근 정보에 더 집중
- 학습률이 0에 수렴하지 않도록 최근 기울기를 더 강조해 안정적인 업데이트 제공
장점
- AdaGrad보다 지속적으로 학습 가능
- 순환신경망(RNN)에 잘 맞음
- 비등방성 데이터 세트에도 강함
단점
- 하이퍼파라미터(감쇠율 등) 튜닝 필요
Adam (Adaptive Moment Estimation)
- 모멘텀 + RMSProp의 장점을 결합
- 학습률을 파라미터마다 적응적으로 조절, 과거 기울기의 지수 가중 평균을 사용
- 1차 모멘트(기울기 평균) + 2차 모멘트(분산) 둘 다 사용
- 초기 단계에서 모멘트가 0에 치우치는 현상을 보정하기 위해 편향 보정(Bias Correction)을 수행
- 2차 모멘트(second moment) → gradient²의 지수이동평균, 2차 미분 정보를 의미하는 것은 아님
- 가중치 감소를 위해 규제 기법을 사용 (Weight Decay)
장점
- 대부분의 딥러닝 모델에서 기본 선택
- 큰 데이터나 고차원 공간에서도 잘 작동
- 빠르고 안정적
- 학습률 자동 조정
단점
- 가끔 일반화 성능이 SGD보다 떨어질 수 있음
- β 값 등에 민감할 수 있음
Nadam (Nesterov + Adam)
- Adam에 Nesterov 가속 기법을 추가한 버전.
- Adam의 모멘텀 + NAG의 예측적 기울기
장점
- Adam보다 더 빠르고 정밀한 수렴 가능
- overshooting 감소
* overshoointg : 학습 중에 가중치 업데이트가 너무 크게 일어나서 최적점(최소 loss)을 지나쳐 버리는 현상
단점
- Adam보다 계산 복잡도 ↑
- 항상 성능 향상되는 건 아님

Adam = 기본값처럼 가장 많이 쓰는 최적화 알고리즘
Nadam = Adam + 더 빠른 수렴이 필요할 때
RMSProp = RNN이나 시계열에 강함
Momentum/NAG = SGD 개선 목적
AdaGrad = 희소 데이터 전용, 단독 사용은 드뭄
SGD + 관성 = Momentum
Momentum + 미래 위치 기울기 = NAG
SGD + 파라미터별 학습률 = AdaGrad
AdaGrad + 최근 정보 반영 = RMSProp
Momentum + RMSProp = Adam
Adam + NAG = Nadam
'개발 > Python' 카테고리의 다른 글
| 이미지 생성형 AI 모델 (0) | 2025.10.06 |
|---|---|
| 주요 합성곱 신경망 (0) | 2025.10.06 |
| 활성화 함수 (0) | 2025.10.06 |
| 집합 연산 (0) | 2025.10.05 |
| groupby + agg로 여러 컬럼 집계하기 (0) | 2025.10.05 |


댓글