CNN
- 연속된 층이 부분적으로 연결 → 가중치 재사용 → DNN보다 적은 파라미터 사용
- 어떤 특성을 감지하면, 이미지의 어느 위치에서든지 감지가 가능 (DNN은 해당 위치만 가능)
- CNN은 주변의 픽셀 정보를 학습 → 이미지 분류에 더 적합
- CNN은 지역적 패턴에 강하지만, 장거리 의존성(Global context)에 한계
- 입력 이미지의 평행이동(translation)에 강인
- 회전(rotation) 변형에 대해 일반적으로 취약
- Convolutional layers (Conv) : 합성곱 계층, 이미지에서 특징(feature) 추출
- Pooling layers (Max/Avg Pooling) : 특징 맵의 크기 축소, 중요한 정보 요약
- Fully Connected layers (FC) : 완전 연결층, 추출된 특징을 기반으로 최종 예측
* 이미지가 회전하면 픽셀 위치와 feature map이 바뀌어 flatten 벡터가 바뀜 → FC 층도 회전에 취약, 분류 성능 ↓
AlexNet (2012) : CNN의 대중화, ReLU+Dropout
VGGNet (2014) : 깊은 네트워크, 작은 필터 반복
GoogLeNet / Inception (2014) : 멀티 스케일 특징, 파라미터 효율
ResNet (2015) : Residual Block → 매우 깊은 네트워크 가능
DenseNet (2017) : 모든 층 연결, feature reuse
MobileNet / Xception (2017) : 경량화, 모바일 최적화
EfficientNet (2019) : Compound Scaling, 효율과 성능 균형
Vision Transformers (ViT, 2020) : CNN 없이 Transformer 적용, 글로벌 특징 학습

AlexNet (2012)
- 8개의 학습 가능한 층: 5개의 합성곱 층(Convolutional layers) + 3개의 완전 연결 층(Fully Connected layers)
- AlexNet의 첫 번째 컨볼루션 층(CONV1)에서 11x11 크기의 커널(필터)을 사용
- 두 번째 층(CONV2)에서는 5x5, 세 번째 층(CONV3)부터는 3x3 크기의 커널을 사용
- 합성곱 층 위에 풀링 층을 쌓지 않고 합성곱 층을 다시 추가
- ReLU 활성화 함수 사용 (기존 Sigmoid보다 학습 속도 빠름)
- ReLU 후, Local Response Normalization (LRN, 경쟁적인 정규화) 적용
- LRN은 가장 활성화된 뉴런이 동일 위치의 뉴런을 억제, 하위 층에서 사용
- Max Pooling 사용으로 차원 축소
- 과적합 방지 = Dropout 사용 + 데이터 증식 (훈련 이미지를 랜덤하게 여러 간격으로 이동 / 뒤집기)
- GPU 사용, 대규모 데이터세트를 빠르게 처리 (학습 시간 단축)
- 입력: 224×224×3 RGB 이미지
특징
- 이미지넷 (ImageNet) 대회에서 1위를 차지하며 CNN의 대중화를 이끈 모델
- GPU 병렬 학습을 적극 활용
- 비교적 깊지 않음(8층)
장점
- ReLU + Dropout으로 학습 속도와 일반화 성능 향상
- CNN이 대규모 이미지 분류에 강력함을 증명
단점
- 깊이가 얕아 표현력이 제한적
- 최신 모델 대비 연산량이 많음
- LRN 사용이 요즘 기준에서는 큰 효과 없음

VGGNet (2014)
- 16 ~ 19층 깊은 CNN
- 3×3 작은 커널 연속 합성곱 사용 (모든 합성곱 층)
- 2×2 Max Pooling로 공간 크기 축소 (풀링 층)
- 여러 개의 연속된 합성곱 층 사용으로 고수준의 특징 추출 → 더 깊은 네트워크에서 복잡한 패턴 학습
- Fully Connected 3층
- 입력: 224×224×3 RGB 이미지
- VGG16, VGG19 등 변형 존재
특징
- 작은 필터(3×3)와 깊은 네트워크 조합으로 성능 향상
- 계층 구조 단순하고 일관됨
- 특징 맵이 커질수록 채널 수 증가 (64 → 128 → 256 → 512)
장점
- 단순하고 이해하기 쉬운 구조
- 작은 필터를 반복하여 깊이 있는 특징 학습 가능
- 전이학습(Transfer Learning)에 좋음
단점
- 파라미터 수가 약 1억 개 이상 → 메모리, 계산량 부담
- 깊이에 따른 학습 어려움 (Vanishing Gradient 문제 발생 가능)
- 연산 비용이 큼

GoogLeNet / Inception (2014)
- Inception Module: 1×1, 3×3, 5×5 합성곱과 3×3 MaxPooling을 병렬로 연결
- 다양한 receptive field를 통해 작은 패턴부터 큰 패턴까지 다양한 스케일의 특징을 동시에 추출
- 22층 깊이지만 파라미터 수는 상대적으로 적음
- Auxiliary Classifier : 중간층에 분류기 두어 학습 안정화

특징
- 다양한 크기의 필터를 동시에 사용
- 연산 효율적, 깊은 네트워크 가능
- 모든 합성곱 층은 ReLU
장점
- 파라미터 효율적
- 여러 스케일의 특징 학습 가능
단점
- 구조가 복잡하여 구현 어려움
- 최신 모델 대비 성능 제한적
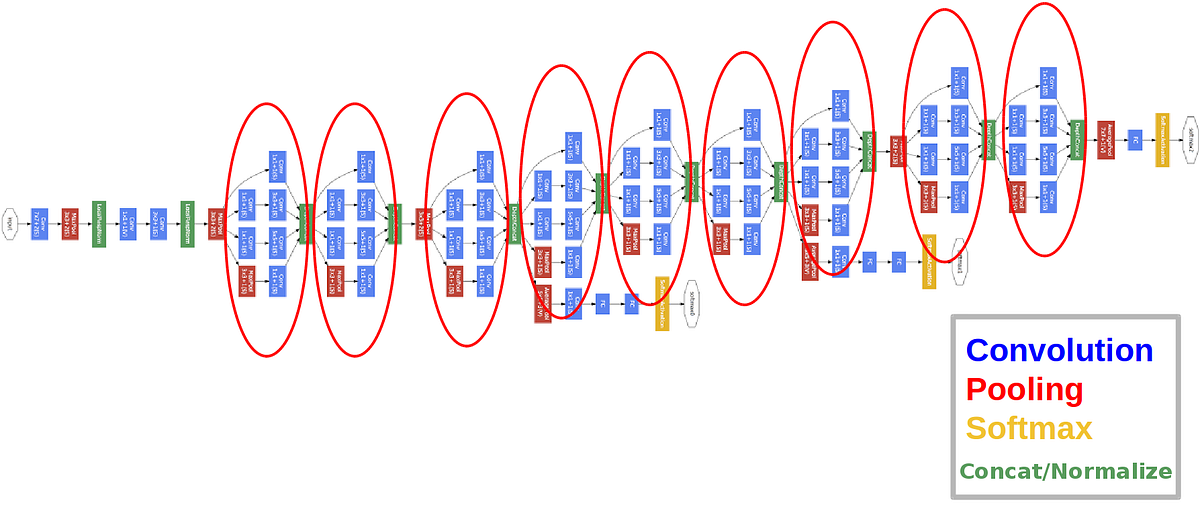
ResNet (Residual Network, 2015)
- Residual Block (Conv → BN → ReLU → Conv → BN → Skip Add → ReLU)
- 입력 x → 합성곱 연산 → 출력 y → x + y (skip connection)
- 잔차 블록(Residual Block)은 입력값을 네트워크에 통과시킨 후, 원래의 입력값에 더하는 구조
- 매우 깊은 네트워크 가능 (50, 101, 152층)
- Batch Normalization 사용
- ReLU 활성화 사용
특징
- 스킵 연결(skip connection, shortcuts)로 기울기 소실 문제 해결
- 매우 깊은 CNN도 학습 가능
- ResNet50, ResNet101 등 변형
장점
- Vanishing Gradient 문제 해결
- 깊은 네트워크 가능 → 더 강력한 표현력
- 전이학습에서 매우 강력
단점
- 구조 단순하지만 깊이가 깊으면 연산량과 메모리 부담
- 작은 데이터셋에서는 과적합 위험

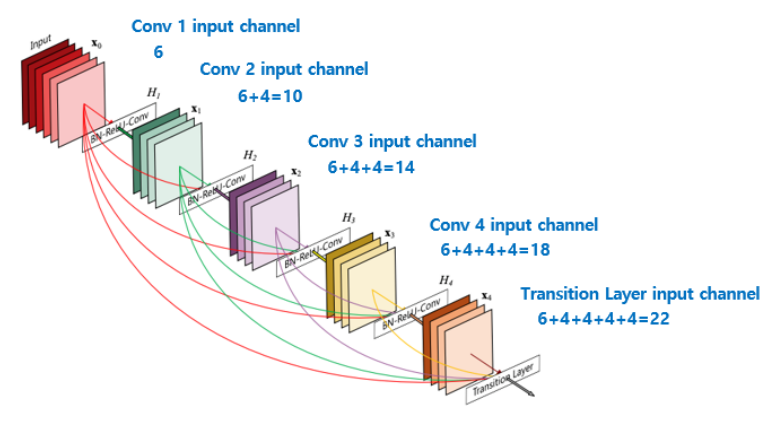
DenseNet (2017)
- Dense Block: 이전 층의 출력을 모든 이후 층으로 연결
- 각 층에서 feature reuse 가능
- 층 수 대비 파라미터 효율적
특징
- 모든 층이 서로 연결 → Gradient 흐름 원활
- Feature reuse → 학습 효율 증가
장점
- Vanishing gradient 문제 해결
- 적은 파라미터로 높은 성능
- 전이학습에 강함
단점
- 메모리 사용량 많음 (모든 층 연결)
- 매우 깊은 DenseNet 학습 시 연산량 증가
MobileNet (2017)
- Depthwise Separable Convolution: 일반 합성곱 → depthwise + pointwise
- 경량화 네트워크 → 모바일 환경 최적화
특징
- 연산량과 파라미터를 크게 줄임
- 실시간 이미지 처리 가능
장점
- 모바일/임베디드 환경 적합
- 빠른 추론 속도
단점
- 복잡한 특징 학습 한계 → 일반 CNN보다 성능 낮을 수 있음
Xception (2017)
- Extreme Inception → Depthwise Separable Convolution (깊이별 분리 합성곱)
- Inception보다 간단하고 효율적
특징
- 특징 맵 재사용 및 경량화
- ResNet 아이디어와 결합 가능
장점
- 효율적, 깊은 네트워크 가능
- 전이학습 활용도 높음
단점
- 연산량 여전히 있음
- 작은 데이터셋에서는 과적합 위험
EfficientNet (2019)
- Compound Scaling: Depth, Width, Resolution 동시에 최적화
- 기본 EfficientNet-B0부터 B7까지 확장
특징
- 성능 대비 파라미터 효율 최고 수준
- 기존 CNN보다 적은 파라미터로 높은 정확도
장점
- 효율적(작은 모델로도 성능 좋음)
- 다양한 스케일 지원
단점
- 구조 설계 복잡
- 하드웨어 최적화 필요
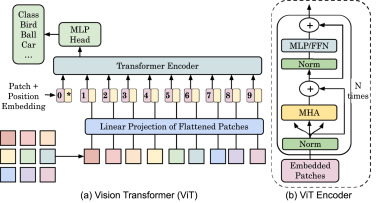
Vision Transformers (ViT, 2020)
- 이미지 → 패치(Patch) 분할 (예: 16×16)
- 각 패치를 1D 벡터로 변환 → 포지션 임베딩(Position Embedding) 추가
- Transformer Encoder에 입력 (Self-Attention)
- MLP Head → 분류 결과 출력
특징
- CNN 없이 Transformer 적용
- Attention을 통해 이미지 내 전역적 관계(global relationship) 학습 가능 (Self Attention 메커니즘으로 상호작용 학습)
- 포지셔널 인코딩을 추가하여 순서와 위치 정보를 모델에 제공
- 데이터가 충분할 때 CNN보다 강력
장점
- 패치 벡터를 통해 전역적 특징 학습 가능 → 멀리 떨어진 객체 관계도 포착 (CNN은 이미지의 공간적 계층 구조로 정보를 처리)
- 단순한 구조로 모델 확장 용이
- Pretraining + Fine-tuning으로 강력한 성능 발휘
단점
- 학습 데이터가 많아야 성능 좋음 (ImageNet-21k 등)
- 연산량 많음 (특히 고해상도 이미지)
- 작은 데이터셋에서는 CNN보다 성능 떨어질 수 있음
'개발 > Python' 카테고리의 다른 글
| 과대적합 해결 방법 (0) | 2025.10.08 |
|---|---|
| 이미지 생성형 AI 모델 (0) | 2025.10.06 |
| 경사 하강법, 옵티마이저 (0) | 2025.10.06 |
| 활성화 함수 (0) | 2025.10.06 |
| 집합 연산 (0) | 2025.10.05 |



댓글