반응형
부스팅
- 여러 개의 약한 학습기를 순차적으로 학습시켜 강한 학습기로 만드는 앙상블 방법
- 오류 데이터에 더 큰 가중치를 부여하여 다시 샘플링
- 약한 학습기 : weak learner, 조금만 잘 맞는 모델 (예: 깊이가 낮은 결정트리)
- 강한 학습기 : strong learner, 여러 약한 학습기를 합쳐 높은 정확도를 내는 모델


다음 데이터에 대해 부스팅을 4번 적용하라. (결정 트리, 최대 깊이 5 모형)
import pandas as pd
import numpy as np
np.random.seed(1234)
X = np.random.randn(500, 5) # 500개 샘플, 5개 변수
y = np.random.choice([0, 1], size=500)
df = pd.DataFrame(X, columns=[f'X{i+1}' for i in range(5)])
df['y'] = y
df
훈련 세트와 테스트 세트는 다음과 같이 나누어서 실행하라.
from sklearn.model_selection import train_test_split
TRAIN, TEST = train_test_split(df, test_size=0.2, random_state=1234)최초의 train 데이터로 시작해 모델을 만들고, y_true와 y_pred가 다른 데이터(=error_data)를 train에 추가하면 된다.
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import f1_score
models = []
train = TRAIN.copy()
cols = ['X1', 'X2', 'X3', 'X4', 'X5']
for _ in range(5):
model = DecisionTreeClassifier(random_state=1234, max_depth=5)
model.fit(train[cols], train['y'])
models.append(model)
y_true = train['y']
y_pred = model.predict(train[cols])
print(f1_score(y_true, y_pred))
error_data = train[y_true != y_pred]
train = pd.concat([train, error_data], axis=0)
각 모델의 결과를 결합한 앙상블 모델도 만들 수 있다.
랜덤으로 만든 데이터이기 때문에 반드시 f1_score가 높아지는 것은 아니다.
pred0 = models[0].predict(TEST[cols])
pred1 = models[1].predict(TEST[cols])
pred2 = models[2].predict(TEST[cols])
pred3 = models[3].predict(TEST[cols])
pred4 = models[4].predict(TEST[cols])
pred = ((pred0 + pred1 + pred2 + pred3 + pred4) >= 3) * 1
f1_score(TEST['y'], pred)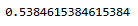
반응형
'개발 > Python' 카테고리의 다른 글
| 선형회귀모형의 검정통계량 F0 (3) | 2025.08.17 |
|---|---|
| 이원분산분석 (Two-Way ANOVA) (1) | 2025.08.16 |
| statsmodels ols 결과 출력하기 (1) | 2025.08.15 |
| 결정 트리 (분기 전후의 지니 불순도 감소량) (1) | 2025.08.15 |
| 일원분산분석 비교 (f_oneway vs anova_lm) (2) | 2025.08.15 |




댓글