병합적 군집분석(AgglomerativeClustering)은 비지도 학습이다.
따라서 지도학습처럼 Train으로 학습하고, Test로 예측할 수 없다. (predict 메서드가 없다.)
그리고 학습 시 생성된 군집의 중심(centroid)이라는 개념도 없다.
하지만 아래의 방법으로 비슷한 효과를 줄 수 있다.
1. Train 데이터로 군집을 만든 후, 각 군집의 중심을 구한다.
2. Test 데이터의 모든 샘플에 대해 계산된 군집 중심과의 거리를 비교해 가장 가까운 군집에 할당한다.
아래 데이터를 Train과 Test로 분리하고 Train으로 학습한 병합적 군집분석 모델을 Test에 적용해보자.
from sklearn.datasets import make_blobs
import pandas as pd
# 5개의 군집 데이터 생성
X, y = make_blobs(
n_samples=100, # 총 샘플 수
centers=5, # 군집 개수
cluster_std=0.6, # 군집 표준편차 (작을수록 더 조밀)
random_state=1234
)
# DataFrame 변환
df = pd.DataFrame(X, columns=["X", "Y"])
df["Cluster"] = y # 실제 군집 레이블 (분석할 땐 사용 안 함)
df
그림으로 나타내면 다음과 같이 5개의 군집으로 구성된 데이터라는 것을 알 수 있다.
import matplotlib.pyplot as plt
plt.scatter(df["X"], df["Y"], c=df["Cluster"], cmap="viridis")
plt.title("make_blobs data")
plt.xlabel("X")
plt.ylabel("Y")
plt.show()
먼저 데이터를 TRAIN과 TEST로 나누자.
from sklearn.model_selection import train_test_split
TRAIN, TEST = train_test_split(df, test_size=0.2, random_state=1234)
그리고 TRAIN에 대해 병합적 군집분석을 적용한다.
from sklearn.cluster import AgglomerativeClustering
agg = AgglomerativeClustering(n_clusters=5, affinity='manhattan', linkage='complete')
agg.fit(TRAIN)
결과를 label에 저장하고 출력하면 Cluster와 label의 값이 모두 일치하지는 않는다.
하지만 Cluster와 label 모두 군집에 대해 임의로 번호가 할당된 것이다.
즉, Cluster의 0과 label의 3이 같은 군집이라고 할 수 있다.
TRAIN['label'] = agg.labels_
TRAIN
이제 TRIAN에 대하여 군집(label)별로 중심 좌표를 구하자.
center = TRAIN.groupby('label')[['X', 'Y']].mean().reset_index()
center
위에서 구한 중심의 좌표(center)와 TEST 데이터의 각 행의 거리를 계산한다.
각 행별로 중심의 좌표 중 가장 가까운 거리에 label을 할당하면 된다. (euclidean 거리 이용)
from scipy.spatial.distance import euclidean
TEST['min_dist_label'] = 0
for i, row in TEST.iterrows():
r = row[['X', 'Y']]
dist_list = []
for k, c_row in center.iterrows():
cr = c_row[['X', 'Y']]
dist = euclidean(r, cr)
dist_list.append(dist)
min_label = np.array(dist_list).argmin()
TEST.loc[i, 'min_dist_label'] = min_label
TEST
replace를 이용해 Cluster와 min_dist_label의 번호를 일치시키면 Test의 군집이 잘 할당된 것을 알 수 있다.
TEST['Cluster'] = TEST['Cluster'].replace({0: 3, 3: 4, 4: 1, 1: 0})
참고
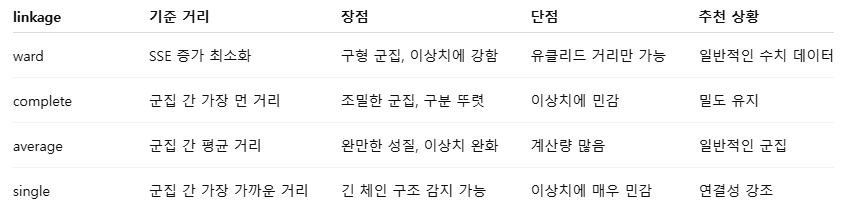
linkage 옵션 정리
'개발 > Python' 카테고리의 다른 글
| SVM Hyper Parameters and Attributes (1) | 2025.08.14 |
|---|---|
| 선형회귀모형의 변수 선택 (후진제거법, 전진선택법) (1) | 2025.08.14 |
| Pandas 전처리 - 이상치 탐지 (4) | 2025.08.12 |
| 그룹 별 변수들의 차이 비교 (일원분산분석 vs Kruskal-Wallis 검정) (4) | 2025.08.10 |
| Pandas 전처리 - 결측치 처리 (1) | 2025.08.10 |




댓글