결측치는 여러 방법으로 처리가 가능하다.
- 제거
- 평균, 중앙값, 최빈값, 상수값 대체
- Hot Deck : 비슷한 특성을 가진 다른 관측값에서 무작위로 대체
- Regression : 다른 변수로 회귀 예측하여 대체 (LinearRegression)
- K-NN : K 최근접 이웃 알고리즘으로 결측치 주변 데이터를 평균값으로 대체 (KNNImputer)
- Interpolation : 보간법 (interpolate())
- EM Algorithm : 확률 기반 반복추정으로 대체 (statsmodels, fancyimpute)
- Multiple imputation (MICE) : 결측치를 여러 번 대체 수행하여 결측치의 불확실성을 반영 (IterativeImputer)
다중대치(Multiple Imputation, MI)
- 여러 개의 plausible(가능한) 값으로 여러 번 대치하여 불확실성을 반영하는 방법
- 추정값의 분산을 적절히 증가
- 유의수준과 신뢰구간을 더 정확하게 반영
- 대치 단계 (Imputation) : 결측치를 예측 모델로 여러 개(M번) 대치하여 M개의 완성 데이터셋 생성
- 분석 단계 (Analysis) : 각 데이터셋을 동일한 통계 분석법으로 분석
- 결합 단계 (Pooling) : 각 분석 결과를 Rubin의 공식으로 결합하여 최종 결과 도출
결측치 유형
MCAR (Missing Completely At Random, 완전히 무작위 누락)
- 누락이 데이터의 어떤 특성과도 관련 없음
- 설문자가 동전을 던져 앞면이 나오면 특정 질문을 무조건 건너뜀
- 삭제해도 편향 없음, 데이터가 줄어 효율성(표본 수) 감소
MAR (Missing At Random, 조건부 무작위 누락)
- 누락 여부가 관측된 다른 변수들에는 의존하지만, 누락된 값 자체와는 무관
- 결혼 여부 목록에 미혼인 경우는 자녀 항목을 건너뛰는 경우
- 적절한 모델링 / 대체 가능. 삭제도 가능하지만 주의 필요 (관측된 변수로 보정 가능할 때)
MNAR (Missing Not At Random, 비무작위 누락)
- 누락 여부가 누락된 값 자체 또는 관측되지 않은 정보에 의존
- 자녀 항목이 누락되었는데, 결혼 여부 항목이 없어서 원인을 설명할 수 없음
- 삭제하면 심각한 편향 발생 (누락 자체가 정보)
예제
- 특정 원소 결측치 확인
- 결측치가 존재하는 행 삭제
- 결측치가 N개 이상인 행 삭제
- 결측치의 비중이 N% 이상인 행 삭제
- 그룹별 평균값 대체
- 이전, 이후 값으로 대체
예제 0
다음 데이터에서 특정 원소 하나만 결측치인지 확인해보자.
import pandas as pd
import numpy as np
# 예시 DataFrame
df = pd.DataFrame({
'A': [1, 2, np.nan],
'B': [4, np.nan, 6]
})
df
특정 원소 하나가 결측치인지 확인하는 방법 DataFrame의 isna() (= isnull())에 원소를 넣어서 확인하면 된다.
pd.isna(df.loc[2, 'A']) # True예제 1
아래 데이터에서 결측치가 하나 이상 존재하는 행을 삭제하라.
import pandas as pd
import numpy as np
np.random.seed(1234)
rows = 10
cols = 2
data = np.random.randn(rows, cols)
# 20% 확률로 결측치 삽입
mask = np.random.rand(rows, cols) < 0.2
data[mask] = np.nan
# DataFrame 생성
df = pd.DataFrame(data, columns=[f"X_{i}" for i in range(cols)])
df
dropna()로 쉽게 해결할 수 있다.
df_na = df.dropna()
df_na
예제 2
결측값을 가지는 컬럼의 개수를 행 별로 집계하고, 결측 컬럼이 2개 이하인 행만 남겨라.
import pandas as pd
import numpy as np
np.random.seed(1234)
rows = 100
cols = 5
data = np.random.randn(rows, cols)
# 30% 확률로 결측치 삽입
mask = np.random.rand(rows, cols) < 0.3
data[mask] = np.nan
# DataFrame 생성
df = pd.DataFrame(data, columns=[f"X_{i}" for i in range(cols)])
df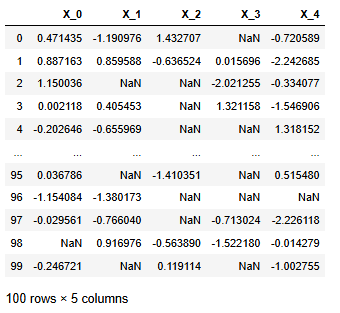
isnull()을 실행하고 행 별(axis=1)로 sum()을 하면 각 행 별 결측치의 개수를 알 수 있다.
df.isnull().sum(axis=1)
개수가 2보다 작은 행만 남기면 17개의 행이 삭제된다.
cnt = df.isnull().sum(axis=1)
df_del = df[cnt <= 2].copy()
df_del
예제 3
각 컬럼별로 결측치의 비중을 구하고, 결측치의 비중이 30%를 초과하는 컬럼을 제거하라.
5개의 column이 있는 100개의 데이터에 아래와 같은 결측치가 있다고 가정한다.
import pandas as pd
import numpy as np
np.random.seed(1234)
rows = 100
cols = 5
data = np.random.randn(rows, cols)
# 30% 확률로 결측치 삽입
mask = np.random.rand(rows, cols) < 0.3
data[mask] = np.nan
# DataFrame 생성
df = pd.DataFrame(data, columns=[f"X_{i}" for i in range(cols)])
df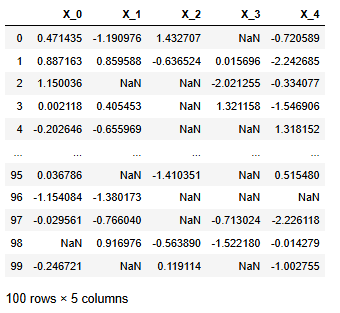
결측치의 비중은 isnull()과 mean()을 이용하여서 구할 수 있다.
결측치의 비중이 30%를 초과하는 컬럼은 X_0, X_3인 것을 알 수 있다.
df.isnull().mean().reset_index(name='val')
위의 데이터 프레임을 tmp라고 하고, 비중이 30% 이하인 컬럼(=index)만 list 형태로 가져온다.
tmp = df.isnull().mean().reset_index(name='val')
cols = tmp[tmp['val'] <= 0.3]['index'].tolist()
cols
결측치가 30% 이하인 컬럼만 원본 데이터 프레임에서 가져오면, 30%를 초과하는 컬럼은 사라지게 된다.
출력 결과 X_0, X_3 컬럼이 제거되었다.
df_del = df[cols]
df_del
예제 4
아래 데이터에 대해 결측치를 제외한 각 그룹별 평균값으로 결측치를 대체하라.
import pandas as pd
import numpy as np
# 예시 데이터 생성
df = pd.DataFrame({
'Group': ['A', 'B', 'A', 'B', 'A', 'B', 'C', 'C', 'A', 'B', 'C'],
'Value': [1.0, np.nan, 3.0, 4.0, np.nan, np.nan, 7.0, 8.0, 1.0, 4.0, 7.0]
})
df
groupby를 이용해서 각 그룹별 Value의 평균을 구하면 다음과 같다.
df_g = df.groupby('Group')['Value'].mean()
df_g
하지만 이 결과를 결측치로 대체하긴 까다롭다.
대신 transform을 이용하면 각 행별로 A, B, C의 평균값을 얻을 수 있다.
df_g = df.groupby('Group')['Value'].transform('mean')
df_g
이제 fillna()를 이용해 결측치를 처리하면 된다.
값 비교를 위해 'Value_filled' 컬럼을 만들어서 비교하였다.
결측치가 아닌 행은 원본 값으로 나오고, 결측치였던 값은 그룹별 평균값으로 대체되었다.
df['Value_filled'] = df['Value'].fillna(df_g)
df
예제 5
1. 다음 데이터에 대해 이전의 행 중 마지막으로 결측이 아닌 데이터로 결측치를 대체하라.
2. 다음 데이터에 대해 이후의 행 중 처음으로 결측이 아닌 데이터로 결측치를 대체하라.
import pandas as pd
import numpy as np
data = {
'A': [np.nan, 2, np.nan, 4],
'B': [1, np.nan, 3, np.nan],
'C': [np.nan, 1, 2, np.nan]
}
df = pd.DataFrame(data)
df
1. fillna에서 method를 ffill로 선택하면 된다.
# forward fill : 이전 값을 가져와서 결측값 채움
df = df.fillna(method='ffill')
df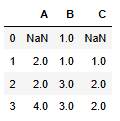
2. fillna에서 method를 bfill로 선택하면 된다.
# backward fill : 다음 값을 가져와서 결측값 채움
df = df.fillna(method='bfill')
df
다음 데이터에 대해 ID 별로 선형 보간법을 이용하여 결측치를 대체하라
import pandas as pd
import numpy as np
np.random.seed(1234)
df = pd.DataFrame({
'ID': np.random.randint(0, 10, size=100),
'Value': np.random.randn(100) # 임의의 값
})
n_missing = int(0.2 * df.shape[0])
missing_indices = np.random.choice(df.index, n_missing, replace=False)
df.loc[missing_indices, 'Value'] = np.nan
df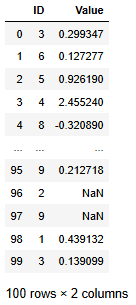
ID별로 데이터를 필터링하고, interpolate()을 이용해서 해결할 수 있다.
df_new = pd.DataFrame()
for _id in df['ID'].unique():
tmp = df[df['ID'] == _id].copy() # id별 데이터
tmp['interpolate'] = tmp['Value'].interpolate(limit_direction='both') # 선형 보간법 적용
df_new = pd.concat([df_new, tmp], axis=0)
df_new
ID가 4인 경우는 아래와 같이 데이터가 변경되었다.
df_new[df_new['ID'] == 4]
'개발 > Python' 카테고리의 다른 글
| 병합적 군집분석 결과를 다른 데이터 샘플에 적용하기 (3) | 2025.08.13 |
|---|---|
| Pandas 전처리 - 이상치 탐지 (4) | 2025.08.12 |
| 그룹 별 변수들의 차이 비교 (일원분산분석 vs Kruskal-Wallis 검정) (4) | 2025.08.10 |
| 빅데이터분석기사 실기 체험 문제풀이 (0) | 2025.06.06 |
| [Kaggle] Pandas Profiling 사용방법 (0) | 2025.01.05 |




댓글