K-Nearest Neighbors
- 비모수 모델 (Non-parametric), 학습 단계에서 모델이 데이터의 분포를 가정하지 않는다.
- Lazy Learning, 학습 단계에서는 거의 계산을 하지 않고, 예측할 때만 계산
- 거리 기반 결정, 새로운 데이터가 들어오면, 학습 데이터 중 가장 가까운 K개의 이웃을 찾고, 분류 또는 회귀
- 실시간 데이터에 강점, 새로운 데이터가 들어와도 바로 예측 가능, 단 학습 데이터가 많으면 느려질 수 있음.
장점
- 단순하고 직관적
- K 값과 거리 측정 방법만 바꿔서 다양한 실험 가능.
- 비모수 모델, 데이터 분포 가정이 필요 없어서 다양한 데이터에 적용 가능
- 다중 클래스 분류 가능
- 학습은 거의 데이터 저장만 하므로 빠름
단점
- 모든 학습 데이터를 대상으로 거리 계산을 해야 하므로, 데이터가 많으면 느려짐
- 메모리 많이 사용, 학습 데이터를 모두 저장
- K 값에 민감 → K가 작으면 노이즈에 민감하고, K가 크면 과도하게 평균화되어 경계가 뭉개짐.
- 거리 척도 선택에 따라 성능이 크게 달라짐
- 차원의 저주에 취약 → 피처(변수)가 많아지면 거리 계산이 의미 없게 되어 정확도가 떨어질 수 있음.
- 특징 스케일링 필요, 거리 기반이므로 피처 값의 단위가 다르면 영향을 많이 받음.
하이퍼 파라미터
from sklearn.neighbors import KNeighborsClassifier, KNeighborsRegressor
KNeighborsClassifier(
n_neighbors=5,
weights='uniform',
algorithm='auto',
leaf_size=30,
p=2,
metric='minkowski',
metric_params=None,
n_jobs=None,
**kwargs,
)
KNeighborsRegressor(
n_neighbors=5,
weights='uniform',
algorithm='auto',
leaf_size=30,
p=2,
metric='minkowski',
metric_params=None,
n_jobs=None,
**kwargs,
)n_neighbors
- kneighbors 질의에 기본적으로 사용할 이웃의 수
weights
- 예측 시 사용되는 가중치 함수
- 'uniform' : 균일 가중치. 각 이웃 내의 모든 점이 동일한 가중치를 가진다.
- 'distance' : 거리의 역수에 의해 점들에 가중치를 부여한다.
이 경우, 질의 지점과 더 가까운 이웃이 멀리 있는 이웃보다 더 큰 영향을 미친다.
- [callable] : 거리 배열을 입력으로 받아, 동일한 형태의 가중치 배열을 반환하는 사용자 정의 함수
import numpy as np
from sklearn.datasets import make_moons
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
X, y = make_moons(n_samples=300, noise=0.25, random_state=0)
# 사용자 정의 weights 함수
def custom_weight(distances):
eps = 1e-5 # 거리 0 회피
return 1 / (distances + eps)**2 # 거리의 제곱의 역수 → 가까울수록 급격히 큰 가중치
knn_custom = KNeighborsClassifier(n_neighbors=5, weights=custom_weight)
knn_custom.fit(X, y)
sample = np.array([[1.5, -0.1]])
print("Custom weighted prediction:", knn_custom.predict(sample))
print("Custom weighted probability:", knn_custom.predict_proba(sample))
def plot_decision_boundary(clf, X, y, title):
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 300),
np.linspace(y_min, y_max, 300))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.3)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolor='k', s=25)
plt.title(title)
plt.show()
plot_decision_boundary(knn_custom, X, y, "KNN with Custom Weights")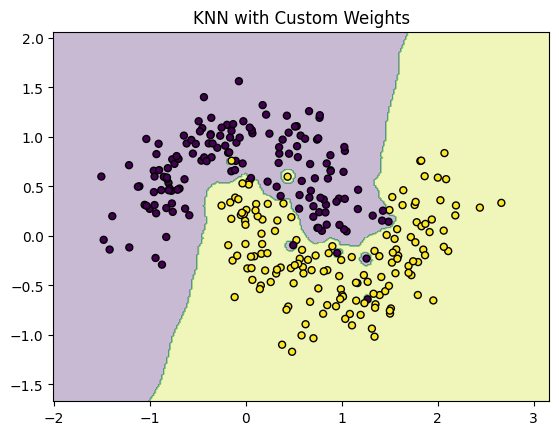
algorithm
- 최근접 이웃을 계산할 때 사용할 알고리즘
- 'ball_tree' : BallTree 를 사용
- 'kd_tree' : KDTree 를 사용
- 'brute' : 브루트 포스(전수 탐색)를 사용
- 'auto' : fit 메서드에 전달된 값에 따라 가장 적절한 알고리즘을 자동으로 선택
leaf_size
- BallTree 또는 KDTree에 전달되는 leaf 크기
- 트리 구성 및 조회 속도, 그리고 트리 저장에 필요한 메모리에 영향을 줄 수 있음
p
- Minkowski 거리의 지수 파라미터
metric
- 트리에 사용할 거리(metric)
metric_params
- metric 함수에 대한 추가 keyword 인자
'개발 > Python' 카테고리의 다른 글
| 분류 모델 평가 옵션 (F1 Score) (0) | 2025.11.21 |
|---|---|
| GradientBoosting Hyper Parameters and Attributes (0) | 2025.11.20 |
| RandomForest Hyper Parameters and Attributes (0) | 2025.11.16 |
| DBSCAN Hyper Parameters and Attributes (0) | 2025.11.15 |
| Distance Matrix (1) | 2025.11.15 |

댓글