f1_score의 파라미터는 다음과 같다.
from sklearn.metrics import f1_score
f1_score(
y_true,
y_pred,
labels=None,
pos_label=1,
average='binary',
sample_weight=None,
)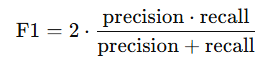
Precision = TP / (TP + FP)
Recall = TP / (TP + FN)
에 대해 average 옵션은 다음과 같다.
binary
- 위와 동일 (pos_label만 계산)
micro
- 전체 TP, FP, FN 합산 후 계산
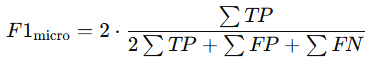
macro
- 클래스별 F1 평균
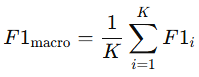
weighted
- 각 라벨에 대해 점수를 계산하고, 각 라벨의 샘플 수(support)로 가중 평균
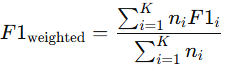
None
- 클래스별 F1 반환
- 클래스명은 사전순으로 자동 정렬 : np.unique(y_true)
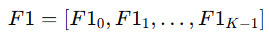
import pandas as pd
from sklearn.metrics import f1_score
# 예시 데이터 (10개 샘플, 3 클래스)
df = pd.DataFrame({
'y_true': [0, 1, 2, 1, 0, 2, 1, 0, 2, 1],
'y_pred': [0, 2, 2, 1, 0, 0, 1, 0, 2, 1]
})
f1_micro = f1_score(df['y_true'], df['y_pred'], average='micro')
f1_macro = f1_score(df['y_true'], df['y_pred'], average='macro')
f1_weighted = f1_score(df['y_true'], df['y_pred'], average='weighted')
f1_none = f1_score(df['y_true'], df['y_pred'], average=None)
print("Micro:", f1_micro)
print("Macro:", f1_macro)
print("Weighted:", f1_weighted)
print("None:", f1_none)
samples
- 한 샘플에 여러 라벨이 동시에 올 수 있는 multi-label classification
- 클래스별이 아니라 샘플 단위 평균
- 샘플마다 여러 라벨이 있을 때, 샘플별 예측 정확도를 F1로 측정하고 평균내는 것
- 각 샘플별로 F1 Score를 계산한 후, 모든 샘플의 F1을 평균

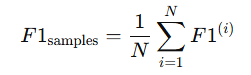
from sklearn.metrics import f1_score
import numpy as np
# 4샘플, 3라벨 multi-label
y_true = np.array([[1,0,1], [0,1,1], [1,1,0], [0,0,1]])
y_pred = np.array([[1,0,0], [0,1,1], [1,0,0], [0,1,1]])
f1_samples = f1_score(y_true, y_pred, average='samples')
f1_samplespos_label
- 데이터가 이진(binary)일 때 사용
- 데이터가 다중 클래스(multi-class)나 다중 라벨(multi-label)인 경우 무시
sample_weight
- 중요도가 높은 샘플에 더 큰 영향을 주고 싶을 때 사용
- 샘플 하나하나마다 가중치를 지정해야 한다. (sample_weight의 길이가 y_true와 동일)
* average='weighted' → 클래스별 support (샘플 수) 가중 평균
from sklearn.metrics import f1_score
import numpy as np
y_true = np.array([0, 1, 1, 0, 1])
y_pred = np.array([0, 1, 0, 0, 1])
# 샘플별 가중치
sample_weight = np.array([1, 2, 1, 1, 3])
# 가중치 적용 F1 계산
f1_w = f1_score(y_true, y_pred, average='binary', pos_label=1, sample_weight=sample_weight)
f1_uw = f1_score(y_true, y_pred, average='binary', pos_label=1) # 가중치 없는 경우
print("가중치 적용 F1:", f1_w) # 0.9090909090909091
print("가중치 없는 F1:", f1_uw) # 0.8→ 마지막 샘플 가중치 3 → F1 계산에서 3배 영향
→ 첫 번째 샘플 가중치 1 → F1 계산에서 기본 영향
'개발 > Python' 카테고리의 다른 글
| LightGBM Hyper Parameters and Attributes (0) | 2025.11.22 |
|---|---|
| AdaBoost Hyper Parameters and Attributes (0) | 2025.11.22 |
| GradientBoosting Hyper Parameters and Attributes (0) | 2025.11.20 |
| K-Nearest Neighbors Hyper Parameters (0) | 2025.11.18 |
| RandomForest Hyper Parameters and Attributes (0) | 2025.11.16 |


댓글