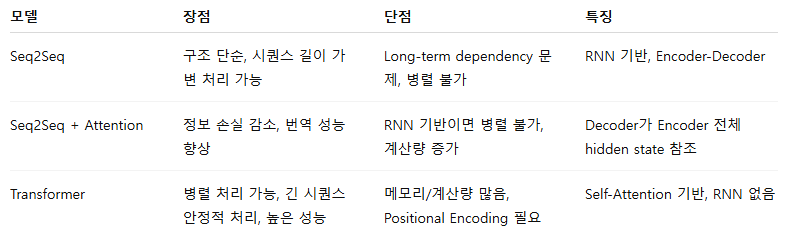
- Seq2Seq → 어텐션 → 트랜스포머: 점점 정보 병목과 연산 한계 개선
- RNN 기반 Seq2Seq는 이해하기 쉽지만 긴 시퀀스 한계
- Attention 도입 → 중요한 정보 선택 가능
- Transformer → 완전 병렬, Self-Attention으로 성능 극대화
Seq2Seq (Sequence-to-Sequence)
- 입력 시퀀스 X=(x1, x2, ..., xn)를 받아 출력 시퀀스 Y=(y1, y2, ..., yn)로 변환하는 모델
- 주로 RNN 계열(LSTM, GRU)로 구성됨

Encoder-Decoder 구조
- Encoder: 입력 시퀀스를 받아 고정 길이 context vector로 압축
- Decoder: context vector를 기반으로 출력 시퀀스 생성
특징
- 순차적 처리: 시간 순서대로 입력과 출력을 처리
- NLP 번역, 요약, 챗봇 등에 사용됨
장점
- 시퀀스 길이가 다른 입력과 출력 처리 가능
- RNN 계열을 사용하면 문맥 정보 반영 가능
한계점
1. Long-term dependency 문제
- 긴 문장의 경우, 고정 길이 context vector가 모든 정보를 담기 어려움
2. 병렬 처리 불가
- RNN 구조 특성상 시퀀스를 순차적으로 처리해야 해서 훈련 속도 느림
3. 정보 손실 가능성
- Encoder에서 context vector에 모든 정보를 담아야 하므로 정보 일부 손실 가능
어텐션 메커니즘 (Attention)
- Decoder가 매 시점마다 Encoder의 모든 hidden state를 참조할 수 있도록 함.
- Context vector가 가중합으로 바뀌어, 필요한 정보에 집중(attend)할 수 있음.
수식 요약

특징
- Seq2Seq의 정보 병목 문제 해결.
- 번역, 텍스트 요약에서 품질 크게 향상.
- RNN 기반 Seq2Seq에 쉽게 통합 가능.
- Self-Attention은 입력 시퀀스의 각 단어가 같은 시퀀스의 모든 단어와 어텐션을 수행, 문맥 상에서 다른 단어와의 관계 학습
Query, Key, Value 세 가지 벡터를 이용
- Query (Q) : "내가 지금 찾고 싶은 정보는 무엇인가? - 현재 데이터"
- Decoder가 현재 시점에서 참조할 정보를 나타냄
- 또는 Self-Attention에서는 같은 시점의 토큰이 다른 토큰과 관계를 볼 때 Q를 생성
- Key (K): "이 정보가 어떤 특성을 가지고 있는가?"
- 각 입력 토큰이 가진 특징을 나타냄
- Q와 얼마나 잘 맞는지 계산할 기준
- 데이터베이스에서 Q와 비교하여 유사도 측정
- Value (V) : "실제 정보 값은 무엇인가?"
- K에 대응하는 실제 정보
- 최종적으로 Q와 K의 유사도로 가중치가 부여되어 합산되는 값


Q는 "내가 보고 싶은 것", K는 "입력 정보의 특성", V는 "실제 값"
장점
- 긴 시퀀스에서도 중요한 정보 선택 가능.
- 시각화 가능 → 모델이 어느 단어에 집중했는지 확인 가능.
- 정보 손실 감소.
한계점
- 여전히 RNN 기반이면 병렬 처리 어려움.
- 계산량 증가: 입력 길이가 길면 attention 연산 비용 증가.
트랜스포머 (Transformer)
- 2017년 Google의 “Attention is All You Need” 논문에서 제안.
- RNN 없이 어텐션만 사용 → 시퀀스 순서 정보 제공을 위한 Positional Encoding 사용
- Self-Attention으로 입력 시퀀스 내 모든 위치 관계 계산.
- Encoder-Decoder 구조 유지하지만 병렬 처리 가능

구조
- Encoder: 여러 층의 Self-Attention + Feed-forward Network
- Decoder: Masked Self-Attention + Encoder-Decoder Attention + Feed-forward
- Positional Encoding: 순서 정보 보존
* Masked Self-Attention : 미래 토큰을 미리 보지 못하도록 신뢰성 있는 생성 보장
특징
- 병렬 처리 가능 → 학습 속도 대폭 향상
- 긴 문장 처리 가능 → Long-term dependency 문제 해결
- NLP뿐 아니라 이미지, 음성 등 다양한 시퀀스 모델링 가능
장점
- 학습 및 추론 속도 빠름.
- 성능 우수 : 번역, 요약, 언어모델(예: GPT, BERT) 기반
- 긴 문장에서도 안정적 성능.
한계점
- 계산량 O(N2) → 긴 시퀀스에 메모리 부담
- Transformer 모델이 크면 학습 비용이 높음
- Positional Encoding 사용으로 시퀀스 길이 제한
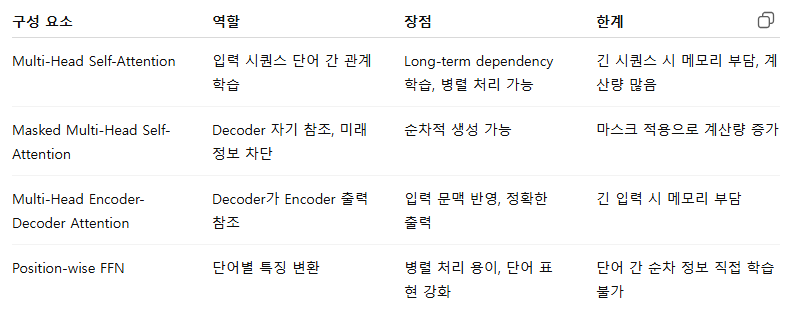
멀티-헤드 셀프 어텐션 (Multi-Head Self-Attention)
- 입력 시퀀스 각 단어가 다른 단어와의 관계를 동시에 여러 관점(head)에서 학습
- Self-Attention: 입력 시퀀스 자체 내 단어 간 관계를 계산

- 멀티 헤드: H개의 서로 다른 Q, K, V 선형 변환 → 병렬 attention 수행 후 concat
- 어텐션을 여러번 동시에 수행

특징
- 여러 관점에서 단어 관계 학습 가능
- 긴 문장도 효과적으로 문맥 반영
- 완전 병렬 처리 가능
장점
- 다양한 의미 관계 캡처 가능.
- Long-term dependency 문제 해결.
한계
- 계산량이 많고 긴 시퀀스 시 메모리 부담
- 구조가 복잡해 학습 비용 높음
포지션 와이즈 피드 포워드 네트워크 (Position-wise Feed-Forward Network)
- 각 위치별로 독립적으로 선형 변환 + 비선형 변환(ReLU)
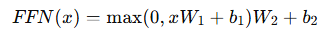
특징
- 위치별 특징 변환
- Self-Attention이 단어 간 관계 학습 후, FFN은 각 단어 표현 강화
- 첫 번째 레이어에서 ReLU, 두 번째 레이어는 활성화 함수가 없음
장점
- 단어별 복잡한 특징 표현 가능
- 병렬 처리 용이
한계
- 순차적 정보 자체는 학습 못함 → Self-Attention과 함께 사용해야 의미 있음
Decoder 구조
- Decoder도 N개의 동일한 층으로 구성되고, Encoder와 거의 유사하나 추가 블록 존재
- 마스크드 멀티-헤드 셀프 어텐션 (Masked Multi-Head Self-Attention)
- 멀티-헤드 인코더-디코더 어텐션 (Multi-Head Encoder-Decoder Attention)
- 포지션 와이즈 피드 포워드 네트워크 (Position-wise FFN)
마스크드 멀티-헤드 셀프 어텐션
- 미래 정보 차단: t 시점의 단어는 t 이후 단어를 참조하지 못함 (이전 단어만을 참고)
- ex) 번역 시, 아직 생성하지 않은 단어는 참고 불가
특징
- Masking → Decoder가 올바른 시퀀스 생성 학습
- Self-Attention과 구조 동일, 단 미래 단어를 0 가중치로 처리
장점
- 자동 완성, 번역 시 정확한 순차 생성 가능
- Teacher Forcing과 함께 학습 가능
한계
- 계산량 증가 (마스크 적용)
- 긴 시퀀스 처리 시 메모리 부담
멀티-헤드 인코더-디코더 어텐션
- Decoder가 Encoder의 출력(hidden state)을 참조
- 디코더가 인코더의 정보에 집중
- Q: Decoder hidden state, K,V: Encoder output
- 출력 시점에서 입력 문장 전체를 참고해 의미 맞춤
특징
- Encoder-Decoder 관계 학습
- 번역, 요약 등 입력과 출력 시퀀스 연관성 반영
장점
- 입력 문맥 정보 반영
- 정확한 시퀀스 생성 가능
한계
- 계산량 증가
- 긴 입력 시 메모리 부담
'개발 > Python' 카테고리의 다른 글
| Ridge, Lasso, Elastic Net (2) | 2025.10.11 |
|---|---|
| 스케일링 (0) | 2025.10.11 |
| PCA vs LDA vs t-SNE (0) | 2025.10.09 |
| 오즈와 오즈비 (0) | 2025.10.09 |
| 순환신경망 RNN (0) | 2025.10.09 |


댓글