랜덤 오버 샘플링 (Random Oversampling)
- 소수 클래스의 데이터를 단순히 복제하여 데이터 수를 늘리는 방법.
- 구현이 매우 간단함.
장점
- 구현이 쉽고 빠름
- 모델이 소수 클래스 데이터를 더 많이 학습할 수 있음
- 데이터 손실 없이 불균형을 개선
단점
- 단순 복제이므로 과적합(Overfitting) 가능성이 높음
- 소수 클래스의 데이터 다양성을 증가시키지 못함
- 복제 데이터 때문에 모델의 결정 경계가 왜곡될 수 있음
SMOTE (Synthetic Minority Over-sampling Technique)
- 소수 클래스의 데이터를 복제하지 않고, 기존 샘플과 가까운 k개의 이웃을 기준으로 새로운 샘플을 생성 (k-NN)
- 소수 클래스의 지역적 구조를 반영하여 샘플 생성 → 다양성 향상, 노이즈나 경계에는 취약
- 소수 클래스 샘플을 랜덤으로 골라 내삽(interploation) 기반으로 새로운 샘플을 생성
- 연속형 변수에 적합
- 범주형 변수에는 부적합 → (대안: SMOTE-NC)

장점
- 데이터 다양성을 증가시켜 과적합 가능성을 낮춤.
- 단순 복제보다 성능 향상 가능.
단점
- 경계가 불명확한 영역에서 잘못된 샘플을 생성할 수 있음.
- 이상치(Outlier)까지 샘플링할 수 있음.
- 소수 데이터들 사이를 선형 보간하여 작동 → 새로운 사례의 데이터 예측에 취약
- 고차원 데이터일수록 잘못된 합성이 더 잦아질 수 있음

ADASYN (Adaptive Synthetic Sampling)
- SMOTE의 약점 보완, 소수 클래스 중 학습이 어려운 샘플 주변에서 더 많은 데이터를 생성.
- 분류가 어려운 소수 클래스 샘플일수록 더 많은 데이터를 생성
- 분류 경계가 애매한 샘플에 더 많은 중요도를 부여하는 방식
- 불균형 비율에 적응적으로 대응

장점
- 모델이 어려운 샘플을 더 잘 학습하게 함.
- 불균형 문제를 더 효과적으로 완화할 수 있음.
단점
- 이상치(outlier)에 집중할 수 있어 노이즈가 많아질 수 있음.
- 고난도 영역을 강화하지만, 데이터 분포를 왜곡할 위험
- SMOTE보다 계산 복잡도가 높음

Borderline-SMOTE
- SMOTE의 변형. 소수 클래스 중 경계(Borderline)에 위치한 샘플만 사용하여 새로운 샘플 생성.
- 경계 - 모델이 혼동할 가능성이 높은 소수 클래스 샘플 주변 영역 (=위험 영역, 다수 클래스와 가까운 소수 클래스 샘플)
- 안전한 샘플보다는 모델 학습에 중요한 경계 샘플을 강화.

장점
- 경계 샘플을 강화하여 분류 성능 향상 가능.
- 불필요한 중복 샘플 생성 최소화.
단점
- 경계 샘플 탐지 과정이 필요해 계산이 약간 복잡함.
- 경계 정의가 잘못되면 성능 저하 가능.
- 경계 근처에 존재하는 이상치가 증가하거나 데이터 분포가 왜곡


import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from imblearn.over_sampling import SMOTE, ADASYN, BorderlineSMOTE
# 1. 다수 클래스/소수 클래스 경계형 데이터 생성
X, y = make_classification(
n_samples=300,
n_features=2,
n_informative=2,
n_redundant=0,
n_clusters_per_class=1,
class_sep=0.5, # 클래스 간 경계가 좁음
weights=[0.8, 0.2],
random_state=42
)
# 소수 클래스 일부를 다수 클래스 근처로 이동해 경계 강조
X[y==1] += 0.3*np.random.randn(sum(y==1), 2)
# 2. SMOTE, ADASYN, Borderline-SMOTE 객체
smote = SMOTE(random_state=42)
adasyn = ADASYN(random_state=42)
borderline = BorderlineSMOTE(random_state=42)
# 3. 오버샘플링 적용
X_smote, y_smote = smote.fit_resample(X, y)
X_adasyn, y_adasyn = adasyn.fit_resample(X, y)
X_border, y_border = borderline.fit_resample(X, y)
# 4. 시각화
fig, axs = plt.subplots(1, 4, figsize=(20, 5))
# 원본 데이터
axs[0].scatter(X[y==0][:,0], X[y==0][:,1], label='Majority', alpha=0.6)
axs[0].scatter(X[y==1][:,0], X[y==1][:,1], label='Minority', alpha=0.6)
axs[0].set_title('Original Data')
axs[0].legend()
# SMOTE
axs[1].scatter(X_smote[y_smote==0][:,0], X_smote[y_smote==0][:,1], label='Majority', alpha=0.6)
axs[1].scatter(X_smote[y_smote==1][:,0], X_smote[y_smote==1][:,1], label='Minority', alpha=0.6)
axs[1].set_title('SMOTE')
# ADASYN
axs[2].scatter(X_adasyn[y_adasyn==0][:,0], X_adasyn[y_adasyn==0][:,1], label='Majority', alpha=0.6)
axs[2].scatter(X_adasyn[y_adasyn==1][:,0], X_adasyn[y_adasyn==1][:,1], label='Minority', alpha=0.6)
axs[2].set_title('ADASYN')
# Borderline-SMOTE
axs[3].scatter(X_border[y_border==0][:,0], X_border[y_border==0][:,1], label='Majority', alpha=0.6)
axs[3].scatter(X_border[y_border==1][:,0], X_border[y_border==1][:,1], label='Minority', alpha=0.6)
axs[3].set_title('Borderline-SMOTE')
plt.show()
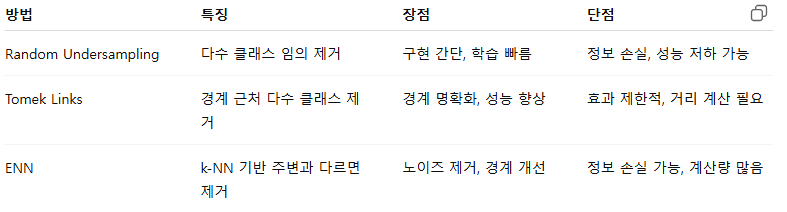
랜덤 언더 샘플링 (Random Undersampling)
- 다수 클래스에서 임의로 데이터를 제거하여 클래스 비율을 맞춤.
- 구현이 매우 간단함.
장점
- 구현이 쉽고 빠름.
- 모델 학습 속도를 높일 수 있음 (데이터 양 감소)
단점
- 중요한 정보가 포함된 다수 클래스 데이터를 제거할 수 있어 성능 저하 가능.
- 단순 제거로 인해 데이터 다양성이 줄어듦 (편향된 경계 형성 위험)
example
from imblearn.under_sampling import RandomUnderSampler
from collections import Counter
import numpy as np
# 예시 데이터 생성
X = np.arange(160).reshape(-1, 1)
y = np.array([0]*100 + [1]*40 + [2]*20)
print("언더샘플링 전:", Counter(y))
# dict로 각 클래스의 목표 샘플 수 지정 (원래 수 이하로)
sampling_dict = {0: 50, 1: 40, 2: 20}
rus = RandomUnderSampler(sampling_strategy=sampling_dict, random_state=42)
X_res, y_res = rus.fit_resample(X, y)
print("언더샘플링 후:", Counter(y_res))
# 언더샘플링 전: Counter({0: 100, 1: 40, 2: 20})
# 언더샘플링 후: Counter({0: 50, 1: 40, 2: 20})Tomek Links
- 서로 다른 클래스 샘플 쌍 중 서로 가장 가까운 이웃을 찾아서, 그 중 다수 클래스 샘플을 제거.
- 데이터 경계에서 중복/노이즈 제거에 초점
- 주로 클래스 분리 개선 목적으로 사용
- Tomek Links : 서로 가장 가까운 이웃인데, 서로 다른 클래스에 속해 있을 때
장점
- 경계 근처의 중복/혼동 데이터 제거(다수 클래스)로 클래스 구분 명확화.
- 단순 랜덤 제거보다 모델 성능에 긍정적.
단점
- 경계 외부의 데이터에는 영향을 주지 않아, 다수 클래스 비율 조정 효과가 약할 수 있음.
- 계산 비용이 큰 편 (거리 계산 필요)

ENN (Edited Nearest Neighbor)
- 각 샘플에 대해 k-최근접 이웃(k-NN)을 확인하고, 주변 다수 클래스 샘플과 클래스가 다르면 제거
- 소수 클래스도 수정 대상이 될 수 있어 언더샘플링 + 데이터 정제 효과
- 노이즈 제거 및 경계 정리에 효과적
장점
- 경계 근처 노이즈와 혼동 샘플 제거에 효과적
- 데이터 품질 개선으로 분류 성능 향상 가능
단점
- 다수 클래스 데이터 많이 제거 시 정보 손실 가능
- k-NN 기반으로 계산량이 증가함

import numpy as np
import matplotlib.pyplot as plt
from imblearn.under_sampling import TomekLinks, EditedNearestNeighbours
# 1. 극적으로 보여주기 위한 2차원 데이터 생성
# 다수 클래스
X_major = np.random.randn(50,2) + [0,0]
# 소수 클래스 (경계 근처)
X_minor = np.random.randn(10,2) + [2,2]
# 노이즈 샘플 (소수 클래스 가까이에 다수 클래스)
X_noise = np.random.randn(5,2) + [2.2,2.2]
X = np.vstack([X_major, X_minor, X_noise])
y = np.array([0]*50 + [1]*10 + [0]*5) # 0=다수, 1=소수
# 2. 원본 데이터 시각화
plt.figure(figsize=(12,4))
plt.subplot(1,3,1)
plt.scatter(X[y==0][:,0], X[y==0][:,1], label='Majority', alpha=0.7)
plt.scatter(X[y==1][:,0], X[y==1][:,1], label='Minority', alpha=0.7)
plt.title('Original Data with Noise & Boundary')
plt.legend()
# 3. Tomek Links 적용
tl = TomekLinks()
X_tl, y_tl = tl.fit_resample(X, y)
plt.subplot(1,3,2)
plt.scatter(X_tl[y_tl==0][:,0], X_tl[y_tl==0][:,1], label='Majority', alpha=0.7)
plt.scatter(X_tl[y_tl==1][:,0], X_tl[y_tl==1][:,1], label='Minority', alpha=0.7)
plt.title('After Tomek Links (Boundary Majority removed)')
plt.legend()
# 4. ENN 적용
enn = EditedNearestNeighbours()
X_enn, y_enn = enn.fit_resample(X, y)
plt.subplot(1,3,3)
plt.scatter(X_enn[y_enn==0][:,0], X_enn[y_enn==0][:,1], label='Majority', alpha=0.7)
plt.scatter(X_enn[y_enn==1][:,0], X_enn[y_enn==1][:,1], label='Minority', alpha=0.7)
plt.title('After ENN (Boundary & Noisy removed)')
plt.legend()
plt.tight_layout()
plt.show()
클래스의 균형을 맞출 경우
→ 모델이 소수 클래스의 패턴을 더 잘 학습
→ 소수 클래스의 recall과 precision이 증가하는 경향이 생긴다. (다수 클래스는 감소)
'개발 > Python' 카테고리의 다른 글
| 오즈와 오즈비 (0) | 2025.10.09 |
|---|---|
| 순환신경망 RNN (0) | 2025.10.09 |
| Batch Normalization vs Layer Normalization (0) | 2025.10.08 |
| 과대적합 해결 방법 (0) | 2025.10.08 |
| 이미지 생성형 AI 모델 (0) | 2025.10.06 |


댓글