반응형
DataFrame의 groupby에서 size와 count를 비교해 보자.
import pandas as pd
data = {
"Group": ["A", "A", "A", "B", "B", "C", "C"],
"Value1": [1, 2, 3, 4, 5, 6, 7],
"Value2": ["x", "y", "z", "w", "v", "t", "u"]
}
df = pd.DataFrame(data)
df
A가 3개 B가 2개 C가 2개이기 때문에 아래의 결과가 나온다.
단순히 개수를 셀 때는 size()와 count() 크게 차이가 없다.
df.groupby("Group").size()
df.groupby("Group").count()
하지만 결측치가 포함된 데이터의 경우 결과가 달라진다.
import pandas as pd
import numpy as np
data = {
"Group": ["A", "A", "A", "B", "B", "C", "C"],
"Value1": [1, 2, np.nan, 4, np.nan, 6, 7],
"Value2": ["x", np.nan, "z", "w", "v", np.nan, "u"]
}
df = pd.DataFrame(data)
df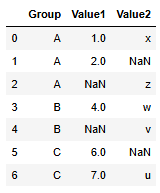
size()는 그룹별 행의 개수를 나타내기 때문에 변화가 없지만,
count()는 그룹별 "결측치를 제외한" 각 컬럼의 값 개수이다.
df.groupby("Group").size()
df.groupby("Group").count()
반응형
'개발 > Python' 카테고리의 다른 글
| 상관계수 (피어슨, 스피어만, 켄달의 타우) (0) | 2025.08.18 |
|---|---|
| Pandas - 데이터 병합 (merge option, inner / left / right / outer) (1) | 2025.08.18 |
| 병합적 군집분석 (노드 별 관측치의 수) (1) | 2025.08.17 |
| 선형회귀모형의 검정통계량 F0 (3) | 2025.08.17 |
| 이원분산분석 (Two-Way ANOVA) (1) | 2025.08.16 |




댓글