반응형
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 부드럽고 단순한 곡선 형태의 데이터 생성
x = np.linspace(0, 10, 100)
# '완만 → 평탄 → 급상승' 느낌의 간단한 함수
y = 0.02*(x-4)**3 + 0.5*x + 1
df = pd.DataFrame({"x": x, "y": y})
# 매끈한 선 그래프
plt.figure()
plt.plot(df["x"], df["y"])
plt.xlabel("x")
plt.ylabel("y")
plt.title("Simple smooth nonlinear curve")
plt.show()
df.head()
비선형적으로 증가하는 데이터이므로 스피어만 상관계수가 1이 나오게 된다.
import pandas as pd
import numpy as np
# 현재 환경에 있는 df를 사용 (이전 셀에서 생성된 데이터)
pearson = df["x"].corr(df["y"], method="pearson")
spearman = df["x"].corr(df["y"], method="spearman")
kendall = df["x"].corr(df["y"], method="kendall")
results = pd.DataFrame({
"상관계수": ["Pearson", "Spearman", "Kendall Tau"],
"값": [pearson, spearman, kendall]
})
results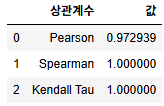
import pandas as pd
import numpy as np
import string
np.random.seed(1234)
columns = list('abcd')
data = np.random.normal(loc=0, scale=1, size=(30, 4))
df = pd.DataFrame(data, columns=columns)
피어슨 상관계수
- 구간척도 이상으로 측정된 두 변수들의 상관관계
- 연속형 변수
- 두 모집단이 정규 분포를 따른다고 가정
- 이상치에 민감
- -1 ~ 1
귀무가설 : 모상관계수 ρ = 0, 두 변수 사이에 선형 상관관계가 없다.
대립가설 : 모상관계수 ρ ≠ 0 (양측검정), 두 변수 사이에 선형 상관관계가 존재한다.
df.corr()
스피어만 상관계수
- 서열척도 변수 상관관계 측정
- 순서형 변수, 비모수적 방법
- 각 표본의 랭킹에 대한 피어슨 상관계수
귀무가설 : 순위 상관계수 ρₛ = 0, 단조 관계가 없다.
대립가설 : 순위 상관계수 ρₛ ≠ 0 (양측검정), 단조 관계가 존재한다.
df.corr(method='spearman')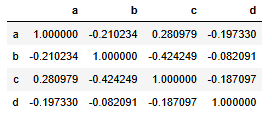
켄달의 타우 상관계수
- 두 변수 간 순서 일치 정도를 측정하는 비모수 상관계수
- 한 변수가 증가할 때 다른 변수도 증가하는 경향이 있는지를 순위 기반으로 평가
- 켄달의 타우는 동률인 데이터가 있을 때에도 적용할 수 있다.
- 타우 값 = -1 ~ 1 사이
귀무가설 : τ = 0, 두 변수 사이에 순위 일치 정도가 랜덤이다. (상관이 없다)
대립가설 : τ ≠ 0 (양측검정), 순위 일치 또는 불일치가 유의미하다. (상관이 있다)
df.corr(method='kendall')


from scipy.stats import kendalltau
# 예시 데이터 (동률 포함)
x = [12, 2, 1, 12, 2] # x에는 12와 2가 각각 두 번 나와 동률 존재
y = [1, 4, 7, 1, 0] # y도 1이 두 번 등장함
tau, p_value = kendalltau(x, y)
print(f"Kendall's tau: {tau:.4f}") # 한 변수가 증가할수록 다른 변수는 감소하는 경향 # -0.4714
print(f"P-value: {p_value:.4f}") # 통계적으로 유의하지 않음 (귀무가설 기각 불가) # 0.2827pvalue
# ex 스피어만 상관계수
from scipy.stats import spearmanr, pearsonr, kendalltau
cols = df.columns.to_list()
for i, v1 in enumerate(cols):
for k, v2 in enumerate(cols):
if k > i:
print(f"{i} vs {k}")
correlation, p_value = spearmanr(df[v1], df[v2])
print(f"Spearman 상관계수: {correlation:.4f}")
print(f"p-값: {p_value:.4f}")
# 결과 해석
if p_value < 0.05:
print("유의미한 순위 상관관계가 있습니다.")
else:
print("유의미한 순위 상관관계가 없습니다.")
print()
반응형
'개발 > Python' 카테고리의 다른 글
| 포아송 분포 문제 예시 (0) | 2025.08.21 |
|---|---|
| ROC 커브의 AUC 계산 (0) | 2025.08.19 |
| Pandas - 데이터 병합 (merge option, inner / left / right / outer) (1) | 2025.08.18 |
| Pandas - groupby size vs count (1) | 2025.08.18 |
| 병합적 군집분석 (노드 별 관측치의 수) (1) | 2025.08.17 |


댓글