반응형
Biplot
- 데이터는 어디에 모여 있고, 그 원인이 되는 변수는 무엇인가를 한 번에 보여주는 그래프
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
# 샘플 데이터 생성
np.random.seed(0)
X = pd.DataFrame({
"Length": np.random.normal(10, 2, 50),
"Width": np.random.normal(5, 1, 50),
"Height": np.random.normal(7, 1.5, 50),
"Weight": np.random.normal(20, 3, 50),
})
# 표준화
X_scaled = StandardScaler().fit_transform(X)
# PCA
pca = PCA(n_components=2)
scores = pca.fit_transform(X_scaled)
loadings = pca.components_.T
# Biplot
plt.figure()
plt.scatter(scores[:, 0], scores[:, 1])
for i, feature in enumerate(X.columns):
plt.arrow(0, 0, loadings[i, 0]*3, loadings[i, 1]*3,
head_width=0.05, length_includes_head=True)
plt.text(loadings[i, 0]*3.2, loadings[i, 1]*3.2, feature)
plt.xlabel("PC1")
plt.ylabel("PC2")
plt.title("PCA Biplot Example")
plt.axhline(0)
plt.axvline(0)
plt.show()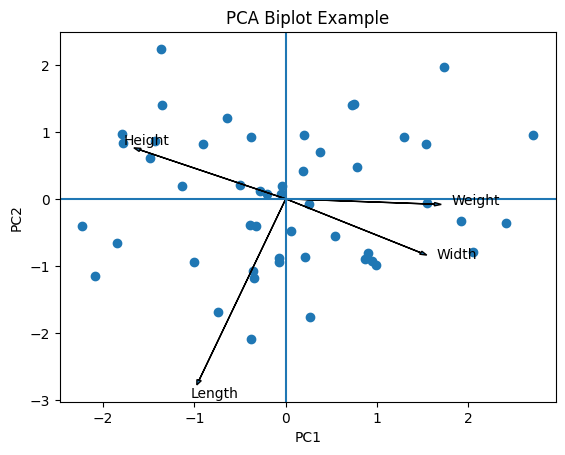
- 각 점은 관측치(sample) 를 의미
- PC1, PC2 공간에서 데이터가 어떻게 분포하는지 보여줌
- 각 화살표는 원 변수(feature)를 의미
- 방향 : 해당 변수가 어떤 주성분에 영향을 주는지
- 길이 : 해당 변수가 주성분에 기여하는 정도
- Weight, Width → PC1 방향 영향 큼
- Length → PC2 음의 방향으로 강한 영향
- Height → PC2 양의 방향 영향
- 화살표 간 각도가 작음 → 양의 상관
- 90도 근처 → 거의 무상관
- 180도 → 음의 상관
USArrests 데이터 셋
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
import statsmodels.api as sm
# 데이터 로딩
data = sm.datasets.get_rdataset("USArrests", "datasets").data
states = data.index
# PCA
X = StandardScaler().fit_transform(data)
pca = PCA(n_components=2)
scores = pca.fit_transform(X)
loadings = pca.components_.T
# 그룹 정의 (질문 번호 기준)
group1 = ["Georgia", "Maryland", "New Mexico"]
group2 = ["Michigan", "Texas"]
group3 = ["Colorado", "California", "New Jersey"]
group4 = ["Idaho", "New Hampshire", "Iowa"]
groups = {
"1. High Murder & Assault": (group1, "red"),
"2. High Rape": (group2, "purple"),
"3. High UrbanPop": (group3, "blue"),
"4. Low Crime & Urban": (group4, "green")
}
# 전체 점 (연한 회색)
plt.figure(figsize=(11, 9))
plt.scatter(scores[:, 0], scores[:, 1], alpha=0.3)
# 그룹별 색상 표시
for label, (states_list, color) in groups.items():
idx = [i for i, s in enumerate(states) if s in states_list]
plt.scatter(scores[idx, 0], scores[idx, 1], label=label, color=color, s=80)
for i in idx:
plt.text(scores[i, 0], scores[i, 1], states[i], fontsize=9)
# 변수 화살표
for i, var in enumerate(data.columns):
plt.arrow(0, 0, loadings[i, 0]*3, loadings[i, 1]*3, head_width=0.05)
plt.text(loadings[i, 0]*3.2, loadings[i, 1]*3.2, var, fontsize=11)
plt.axhline(0)
plt.axvline(0)
plt.xlabel(f"PC1 ({pca.explained_variance_ratio_[0]*100:.1f}%)")
plt.ylabel(f"PC2 ({pca.explained_variance_ratio_[1]*100:.1f}%)")
plt.title("PCA Biplot of USArrests (Grouped Interpretation)")
plt.legend()
plt.show()
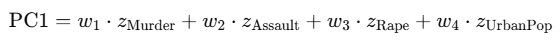
조지아, 메릴랜드, 뉴멕시코
- 폭행과 살인의 비율이 상대적으로 높은 지역
- Georgia, Maryland → PC1 양수
- Murder / Assault 화살표 방향과 가까움
- New Mexico는 Assault보다는 Rape 영향이 더 큼
미시간, 텍사스
- 강간의 비율이 높은 지역
- Rape 화살표는 PC1 양수 + PC2 약간 음수
콜로라도, 캘리포니아, 뉴저지
- 도시에 거주하는 인구의 비율이 높음
- UrbanPop 화살표 방향과 매우 가까움
- PC2 양수 쪽에 위치
아이다호, 뉴햄프셔, 아이오와
- 도시 인구 비율이 낮고 3대 강력범죄도 낮은 지역
- PC1 음수, PC2 음수
참고
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
import statsmodels.api as sm
# 1. 데이터 로딩
data = sm.datasets.get_rdataset("USArrests", "datasets").data
states = data.index
# 2. 표준화
scaler = StandardScaler()
X_scaled = scaler.fit_transform(data)
# 3. PCA
pca = PCA(n_components=2)
scores = pca.fit_transform(X_scaled)
loadings = pca.components_.T
# 4. Biplot
plt.figure(figsize=(10, 8))
# 관측치(주)
plt.scatter(scores[:, 0], scores[:, 1])
for i, state in enumerate(states):
plt.text(scores[i, 0], scores[i, 1], state, fontsize=8)
# 변수(화살표)
for i, var in enumerate(data.columns):
plt.arrow(
0, 0,
loadings[i, 0] * 3,
loadings[i, 1] * 3,
head_width=0.05
)
plt.text(
loadings[i, 0] * 3.2,
loadings[i, 1] * 3.2,
var,
fontsize=10
)
plt.xlabel(f"PC1 ({pca.explained_variance_ratio_[0]*100:.1f}%)")
plt.ylabel(f"PC2 ({pca.explained_variance_ratio_[1]*100:.1f}%)")
plt.title("PCA Biplot of USArrests")
plt.axhline(0)
plt.axvline(0)
plt.show()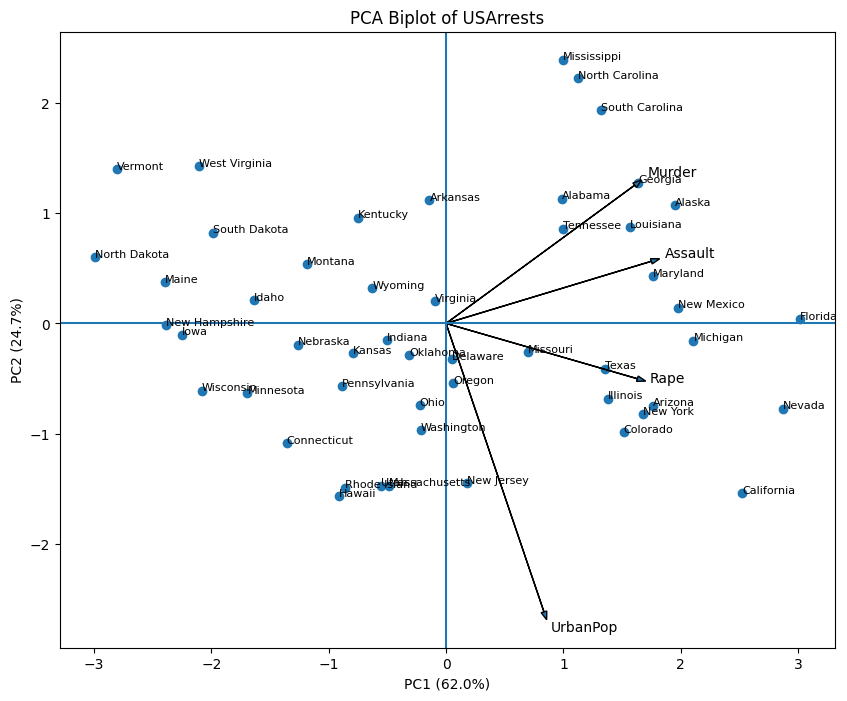
반응형




댓글